Google Cloud Spanner Change Watcher es una biblioteca de código abierto para Google Cloud Spanner para observar y publicar cambios desde una base de datos de Cloud Spanner. Los ejemplos de este artículo requieren la versión 1.1.0 o superior de Spanner Change Watcher.

La biblioteca viene con una aplicación Benchmark de muestra que se puede usar para probar diferentes configuraciones para que Change Watcher pruebe el rendimiento y la carga correspondientes. La aplicación de referencia utiliza una única tabla de ejemplo con un índice secundario que la aplicación de referencia crea automáticamente para simplificar. La tabla y el índice secundario se corresponden con la configuración recomendada en este artículo , y se recomienda leer ese artículo antes de continuar con este artículo para comprender cómo se configura la tabla de muestra.
Este artículo muestra una serie de ejemplos sobre cómo utilizar esta aplicación Benchmark para probar diferentes configuraciones.
Ejecución de la aplicación de referencia
La aplicación Benchmark se encuentra en el proyecto spanner-change-watcher-samples en el repositorio y es una aplicación de consola Java lista para ejecutarse. Tiene dos parámetros de línea de comando obligatorios:
- --instance: la instancia de Cloud Spanner que se usará
- --database: la base de datos de Cloud Spanner para usar
Todos los demás parámetros son opcionales y se pueden utilizar para probar diferentes configuraciones y cargas de escritura.
La base de datos, la tabla y el índice secundario se crearán automáticamente si aún no existen. La aplicación de referencia iniciará dos procesos internamente:
- Un actualizador: el actualizador escribirá cambios aleatorios en la tabla de datos para simular la carga de escritura en la tabla. La carga de escritura del actualizador se puede configurar estableciendo los parámetros transactionPerSecond y mutationsPerTransaction. La configuración predeterminada utilizará un rendimiento de escritura bajo de 1 transacción por segundo y 5 mutaciones por transacción, lo que da un total de 5 mutaciones por segundo en promedio.
- Un observador: el observador sondeará la tabla de datos en busca de cambios escritos por el actualizador. El observador contará el número de cambios que ha visto, pero de lo contrario no hará nada con los cambios. La configuración predeterminada del observador será igual a la configuración recomendada para los observadores de mesas grandes en este artículo .
Ejecución de la aplicación Benchmark usando Maven
La forma más sencilla de ejecutar la aplicación de referencia en su máquina de desarrollo local es utilizar el complemento ejecutivo de Maven. La ejecución de la aplicación de referencia en su IDE también es posible, pero no se recomienda, debido al soporte limitado de la consola en la mayoría de los IDE.
Navegue hasta el directorio spanner-change-watcher / samples / spanner-change-watcher-samples y ejecute el siguiente comando:
mvn exec: java -D.exec.args = "- i mi-instancia -d watcher-benchmark-db"
Esto iniciará la aplicación de referencia con la instancia de Cloud Spanner 'my-instance' y la base de datos 'watcher-benchmark-db' con opciones predeterminadas. 'my-instance' debe ser una instancia existente.
Resultado de la aplicación de referencia
La ejecución de la aplicación de referencia con la configuración predeterminada debería proporcionarle un resultado que se parece aproximadamente a esto:
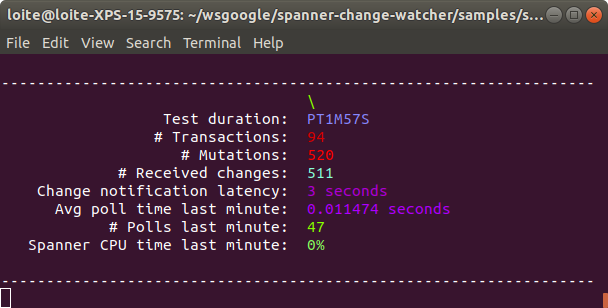
El significado de lo anterior es:
- Duración de la prueba: la cantidad de tiempo que se ha estado ejecutando el punto de referencia.
- # Transacciones: el número de transacciones de escritura que la aplicación ha ejecutado hasta el momento.
- # Mutaciones: el número total de mutaciones que la aplicación ha ejecutado hasta el momento.
- # Cambios recibidos: el número total de cambios que el observador ha recibido hasta el momento. Este número será igual o un poco menor que el número de mutaciones que se han ejecutado cuando inicia el punto de referencia con una base de datos nueva. Las ejecuciones posteriores pueden mostrar una mayor cantidad de cambios recibidos que la cantidad de mutaciones ejecutadas. Esto sucede si detiene la aplicación de referencia mientras hay mutaciones que aún no se han informado. Estos cambios luego se informarán durante la próxima ejecución de referencia.
- Latencia de notificación de cambio: la cantidad de segundos entre la marca de tiempo de confirmación de un cambio y el momento en que se informa del cambio.
- Promedio de tiempo de sondeo en el último minuto: la cantidad promedio de segundos que duró una consulta de sondeo de cambios en la base de datos. Este valor se lee de la tabla SPANNER_SYSQUERY_STATS_TOP_MINUTE.
- Spanner CPU time last minute: un valor calculado que indica la fracción del tiempo total disponible de una sola CPU del total de todas las consultas de sondeo requeridas. Este valor se calcula como (avg_query_time * execution_count) / 60 segundos. El valor no es necesariamente igual a la carga de CPU real en Cloud Spanner .
Prueba de diferentes configuraciones
La aplicación de referencia admite una gran cantidad de parámetros de línea de comandos que se pueden usar para probar diferentes configuraciones de observador y rendimiento de escritura. Los siguientes ejemplos se ejecutaron en una instancia regional de Cloud Spanner de un solo nodo. Los resultados de su propia configuración pueden diferir según el recuento de nodos y la configuración regional o multirregional.
Las opciones de configuración más importantes son:
- transactionPerSecond (w): el número de transacciones de escritura aleatorias que la aplicación debe ejecutar por segundo en promedio. Las transacciones se ejecutarán utilizando un grupo de subprocesos que programará transacciones en momentos aleatorios que, en promedio, coincidirán con el número en esta configuración.
- mutationsPerTransaction (m): el número de mutaciones que cada transacción ejecutará en promedio. El número real de mutaciones por transacción estará en el rango [1, 2 m], con un promedio de m.
- numWatchers (n): la cantidad de observadores diferentes que se utilizarán. La tabla de ejemplo contiene una columna de fragmentación que contiene 37 valores diferentes. Por lo tanto, es posible utilizar hasta 37 observadores diferentes, cada uno de los cuales observa un conjunto separado de valores de fragmentos. La configuración predeterminada utilizará 1 observador que vigila todos los fragmentos, y esto es suficiente para la mayoría de los casos de uso. Si el rendimiento de escritura supera el número máximo de cambios que puede manejar un solo observador, un buen paso siguiente es utilizar varios observadores. La cantidad de mutaciones que puede manejar un solo observador dependerá de la cantidad de nodos en su instancia de Cloud Spanner. La instancia de un solo nodo en este ejemplo puede manejar aproximadamente de 3000 a 5000 mutaciones por segundo.
- pollInterval (p): el intervalo entre cada consulta de sondeo. El valor predeterminado es 1 segundo. Establecer este valor en un intervalo más alto puede reducir la carga en su instancia de Cloud Spanner causada por el observador, ya que se ejecutarán menos consultas de sondeo.
- límite (l): el número máximo de cambios que una consulta de sondeo obtendrá en un sondeo. El valor predeterminado es 10,000. Si regresa una encuesta
número de cambios, se programará una nueva consulta de encuesta inmediatamente después de esta encuesta para obtener lo siguiente cambios. Establecer el límite en un valor más bajo y el intervalo de sondeo en un valor más alto puede ser una buena estrategia para obtener un comportamiento de sondeo más dinámico para las tablas que reciben escrituras en ráfagas. Si, por ejemplo, el intervalo de sondeo se establece en 10 segundos y el límite en 500, la tabla solo se sondeará cada 10 segundos, a menos que la tabla reciba más de 500 mutaciones en un intervalo de 10 segundos.
Configuración predeterminada (recomendada)
La configuración predeterminada de SpannerTableTailer que utilizan las aplicaciones de referencia es la siguiente:
Esta configuración se corresponde con la configuración recomendada que se describe en este artículo .
La siguiente tabla muestra el resultado de la aplicación de referencia usando diferentes cargas de escritura y la configuración predeterminada para el observador. Las pruebas se ejecutaron contra una tabla que ya contenía 17 millones de registros . La necesidad de utilizar un índice secundario al sondear los cambios depende en gran medida del número total de registros de la tabla.
| Cargar | -w | -m | -n | -p | -l | Promedio | CPU | Latencia |
| --------- | ---- | ----- | ---- | ------ | ------- | -------- | ----- | --------- |
| V luz | 1 | 5 | 1 | PT1S | 10000 | 0,0085 | 0% | 1 seg |
| Luz | 5 | 20 | 1 | PT1S | 10000 | 0,0191 | 1% | 1 seg |
| Medio | 10 | 50 | 1 | PT1S | 10000 | 0,0575 | 3% | 1 seg |
| Alto | 25 | 100 | 1 | PT1S | 10000 | 0,2912 | 12% | 2 seg |
| V alto | 50 | 200 | 1 | PT1S | 10000 | 2,1908 | 69% | * |
| V alto | 50 | 200 | 2 | PT1S | 10000 | 0,8298 | 42% | 5 seg |
| V alto | 50 | 200 | 4 | PT1S | 10000 | 0,2791 | 42% | 2 seg |
| V alto | 50 | 200 | 8 | PT1S | 10000 | 0,1355 | 48% | 1 seg |
Los primeros cuatro escenarios de carga de escritura pueden ser manejados por un observador (n = 1). El escenario de carga de escritura 'Muy alta' con 50 transacciones por segundo que escriben 200 mutaciones cada una con un total de 10,000 mutaciones por segundo, no puede ser manejado por un observador en una configuración de Cloud Spanner de un solo nodo. El único observador comenzará a retrasarse cada vez más con respecto a las actualizaciones y la latencia aumentará continuamente. Agregar un segundo observador es suficiente para que el escenario funcione, aunque con una latencia promedio de aproximadamente 5 segundos. Agregar más observadores reducirá aún más esa latencia.
Deshabilitar la sugerencia de tabla / índice secundario
El ejemplo anterior usa la configuración predeterminada para la aplicación Benchmark. Esto significa que el observador de la tabla usará una sugerencia de tabla que indica a Cloud Spanner que use el índice secundario durante la consulta. Si quitamos esta sugerencia de tabla, Cloud Spanner (en el momento de redactar este artículo) de manera predeterminada no usará el índice secundario. Esto tendrá un impacto negativo en el rendimiento de la consulta de la encuesta. El impacto exacto dependerá del número de filas de la tabla. Si está probando esto con una tabla recién creada, obtendrá resultados mucho mejores que si, por ejemplo, deja que la aplicación de referencia se ejecute durante un tiempo con una carga de escritura alta (por ejemplo, -w 25 -m 100).
El parámetro de línea de comando para deshabilitar la sugerencia de tabla es --disableTableHint.
| Cargar | -w | -m | -n | -p | -l | Promedio | CPU | Latencia |
| ------- | ---- | ---- | ---- | ------ | ------- | --------- | - ----- | ----------- |
| Luz | 5 | 20 | 1 | PT1S | 10000 | 85.0711 | 283% | 30-60 segundos |
| Luz | 5 | 20 | 2 | PT1S | 10000 | 80,8160 | 404% | 30-60 segundos |
| Luz | 5 | 20 | 8 | PT1S | 10000 | 80,7088 | 929% | > 60 segundos |
| Luz | 5 | 20 | 37 | PT1S | 10000 | 81,6249 | 910% | > 60 segundos |
La desactivación de la sugerencia de mesa tendrá un impacto dramático en el rendimiento del observador de cambio de mesa. Los valores exactos dependerán en gran medida del número de filas existentes en la tabla que se está observando, ya que la consulta de sondeo utilizará un escaneo completo de la tabla en lugar de utilizar el índice secundario.
Deshabilitar proveedor de fragmentos
También podemos deshabilitar el proveedor de fragmentos que le dice al observador que solo observe los cambios que tienen un valor entre -37 y 37 en la columna de fragmentos. Este proveedor de fragmentos agrega una cláusula WHERE ShardId IN (-37, -36, ..., 36, 37) a la consulta de sondeo, que puede parecer innecesaria al principio. Sin embargo, hace posible que Cloud Spanner escanee el índice secundario de manera mucho más eficiente, ya que le estamos diciendo a Cloud Spanner de antemano que solo necesita buscar estos valores específicos. Si omitimos esto, Cloud Spanner primero debe escanear el índice en busca de todos los valores de fragmentos distintos antes de poder acceder a cada una de las diferentes partes del índice. Alternativamente, Cloud Spanner solo hará un análisis completo de todo el índice.
El parámetro de la línea de comando para deshabilitar la sugerencia de la tabla es --disableShardProvider. Tenga en cuenta que la aplicación de referencia solo le permitirá deshabilitar el proveedor de fragmentos si el número de observadores es 1. De lo contrario, tendría varios observadores mirando la misma parte de la tabla (es decir, toda la tabla). La sugerencia de tabla que indica a Cloud Spanner que use el índice secundario aún se usa y, como es un índice filtrado por nulos, la aplicación de referencia agregará un NotNullShardProvider al observador. Este proveedor simplemente agregará una cláusula WHERE ShardId IS NOT NULL a la consulta de sondeo.
| Cargar | -w | -m | -n | -p | -l | Promedio | CPU | Latencia |
| -------- | ---- | ----- | ---- | ------ | ------- | --------- | ------ | --------- |
| Luz | 5 | 20 | 1 | PT1S | 10000 | 14.0975 | 140% | 11 seg |
| Medio | 10 | 50 | 1 | PT1S | 10000 | 13,7384 | 160% | 10 seg |
| Alto | 25 | 100 | 1 | PT1S | 10000 | 14,8597 | 173% | * |
El observador podrá mantenerse al día con las cargas de escritura bajas y medias, pero la carga de escritura alta lo abrumará. El rendimiento en las cargas de escritura bajas y medias también es mucho peor que cuando se usa un proveedor de fragmentos que especifica cada posible valor de fragmentos.
El uso de NotNullShardProvider en lugar de un proveedor de fragmentos que especifique todos los valores posibles en la columna de fragmentos puede resultar útil en algunos escenarios específicos:
- Si la columna de fragmentos puede contener cualquier valor aleatorio en lugar de solo un conjunto específico de valores. En esos casos, usar un NotNullShardProvider es aún mejor que no usar ningún proveedor de fragmentos.
- Si elimina regularmente elementos más antiguos del índice secundario filtrado por nulos estableciendo la marca de tiempo de confirmación en nulo, NotNullShardProvider funcionará muy bien, ya que todas las entradas no relevantes ya se han eliminado del índice. Consulte la sección correspondiente de este artículo para obtener más información sobre cómo eliminar entradas antiguas de un índice secundario filtrado por nulos.
Aumentar el intervalo de encuesta
Si su tabla no recibe un flujo continuo de escrituras, sino más bien ráfagas de escrituras, puede tener sentido establecer un intervalo de sondeo más alto. Esto hará que una consulta de sondeo regular se ejecute con menos frecuencia, lo que reducirá la carga total en la base de datos. Cada encuesta siempre buscará todos los cambios que estén disponibles, independientemente del límite que se haya configurado. El límite solo determinará cuántos cambios se obtienen en una consulta de sondeo. Si una consulta devuelve cambios de límite, se ejecutará una nueva consulta de sondeo directamente para obtener el siguiente conjunto de cambios. Los siguientes argumentos de la línea de comandos muestran el efecto de esto:
> mvn exec: java -Dexec.args = "\
> -i mi-instancia \
> -d mi-base de datos \
> -w 0,5 -m 500 -l 1000 -p PT10S "
El observador de cambios ejecutará una consulta de sondeo cada 10 segundos con un límite de 1000 cambios como máximo. Si la consulta devuelve 1000 cambios, se ejecutará una nueva consulta de sondeo inmediatamente para recuperar los cambios restantes. Esto se repetirá hasta que una consulta de sondeo haya recibido menos de 1,000 cambios. El observador esperará otros 10 segundos antes de volver a sondear.
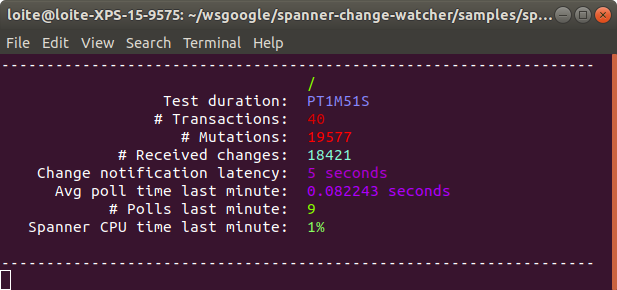
Esto cambiará la latencia de notificación de cambio por menos carga en el backend. La diferencia exacta dependerá de la amplitud de las escrituras en la tabla. Compare con la siguiente captura de pantalla de una ejecución con la siguiente configuración:
> mvn exec: java -Dexec.args = "\
> -i mi-instancia \
> -d mi-base de datos \
> -w 0,5 -m 500 -l 10000 -p PT1S "

Conclusión
La aplicación Benchmark en el directorio de ejemplos de Spanner Change Watcher se puede utilizar para probar diferentes configuraciones para un Spanner Table Watcher en combinación con diferentes cargas de escritura. La configuración predeterminada que se utiliza en la aplicación Benchmark es la configuración recomendada para tablas grandes que reciben una gran cantidad de escrituras. Esta configuración incluye:
- Una columna de fragmentos (calculada) que contiene un conjunto relativamente pequeño de valores fijos. La tabla de ejemplo usa el módulo 19 de un hash de algunos de los datos de la tabla, lo que da un conjunto fijo de valores de fragmentos en el rango [-18, 18].
- Un índice secundario (filtrado por nulos) en la columna de fragmentos y la columna de marca de tiempo de confirmación.
- Un FixedShardProvider con un ARRAY
que contiene todos los valores en el rango [-18, 18]. - Una sugerencia de tabla que fuerza el uso del índice secundario del punto 2 anterior.
Benchmark Spanner Change Watcher se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación destacando y respondiendo a esta historia.