Anteriormente, en la serie BigQuery Explained, analizamos cómo la arquitectura de computación y almacenamiento desacoplada ayuda a BigQuery a escalar sin problemas. Analizamos la administración de almacenamiento de BigQuery, las tablas de partición y agrupación en clústeres para mejorar el rendimiento de las consultas y optimizar el costo. Hasta ahora, solo hemos consultado o utilizado conjuntos de datos que ya existían dentro de BigQuery. En esta publicación, veremos cómo cargar o ingerir datos en BigQuery y analizarlos. ¡Vamos a sumergirnos en ello!
Antes de comenzar, veamos la diferencia entre cargar datos en BigQuery y realizar consultas directamente desde una fuente de datos externa sin cargarlos en BigQuery.
- Importación directa (tablas administradas): BigQuery puede ingerir conjuntos de datos de una variedad de formatos diferentes directamente en su almacenamiento nativo . El almacenamiento nativo de BigQuery está completamente administrado por Google; esto incluye replicación, copias de seguridad, escalado horizontal y mucho más.
- Consulta sin cargar (tablas externas) : el uso de una consulta federada es una de las opciones para consultar fuentes de datos externas directamente sin cargar en el almacenamiento de BigQuery. Puede realizar consultas en los servicios de Google, como Google Sheets, Google Drive, Google Cloud Storage, Cloud SQL o Cloud BigTable, sin tener que importar los datos a BigQuery.
Una diferencia clave es que el rendimiento de la consulta de fuentes de datos externas puede no ser equivalente a la consulta de datos en una tabla nativa de BigQuery. Si la velocidad de la consulta es una prioridad, cargue los datos en BigQuery. El rendimiento de una consulta federada depende del rendimiento del motor de almacenamiento externo que realmente contiene los datos.
Carga de datos en BigQuery
Hay varias formas de cargar datos en BigQuery según las fuentes de datos, los formatos de datos, los métodos de carga y los casos de uso, como por lotes, transmisión o transferencia de datos. En un alto nivel, las siguientes son las formas en que puede ingerir datos en BigQuery:
- Ingestión de lotes
- Transmisión de transmisión
- Servicio de transferencia de datos (DTS)
- Materialización de consultas
- Integraciones de socios
Aquí hay un mapa rápido con opciones para llevar sus datos a BigQuery ( no es una lista exhaustiva ).
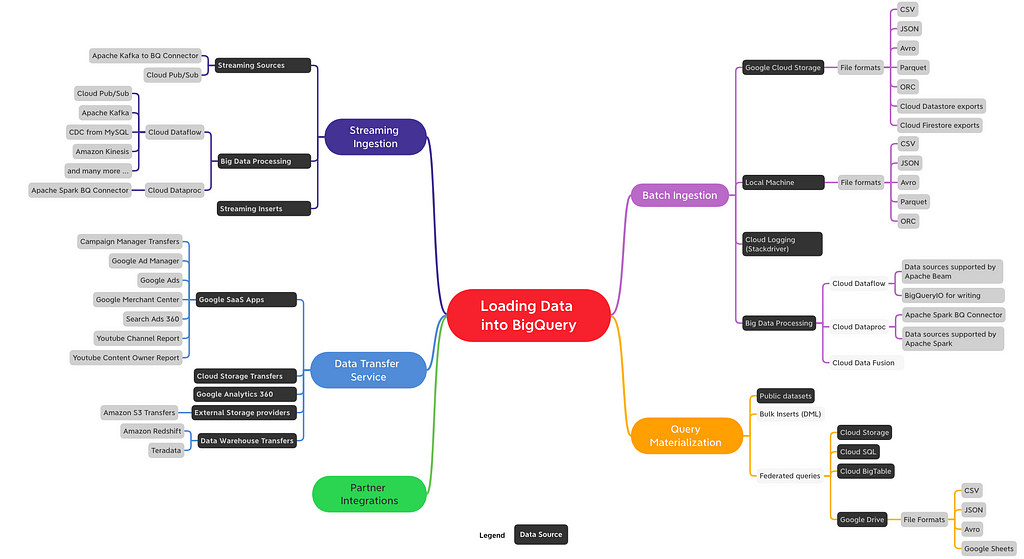
En esta publicación, profundizaremos en la ingestión de lotes e introduciremos otros métodos a un alto nivel. Tendremos publicaciones de blog dedicadas en el futuro para otros mecanismos de ingestión.
Ingestión de lotes
La ingestión de lotes implica cargar conjuntos de datos grandes y limitados que no tienen que procesarse en tiempo real. Por lo general, se ingieren a frecuencias regulares específicas y todos los datos llegan a la vez o no llegan. Luego, los datos ingeridos se consultan para crear informes o se combinan con otras fuentes, incluido el tiempo real.
Los trabajos de carga por lotes de BigQuery son gratuitos. Solo paga por almacenar y consultar los datos, pero no por cargarlos.
Para casos de uso por lotes, Cloud Storage es el lugar recomendado para obtener datos entrantes. Es un servicio de almacenamiento de objetos duradero, de alta disponibilidad y rentable. La carga desde Cloud Storage a BigQuery admite varios formatos de archivo : CSV, JSON, Avro, Parquet y ORC.
¿Cargar archivos comprimidos o sin comprimir?
BigQuery puede ingerir archivos comprimidos (GZIP) y sin comprimir de Cloud Storage. Las operaciones de carga altamente paralelas permiten que los archivos sin comprimir se carguen significativamente más rápido que los archivos comprimidos. Dado que los archivos sin comprimir son más grandes, puede haber posibles limitaciones de ancho de banda y es más caro almacenarlos. Por otro lado, los archivos comprimidos son más rápidos de transmitir y más baratos de almacenar, pero más lentos de cargar en BigQuery. Evalúe las opciones de compresión según su caso de uso: los clientes generalmente eligen archivos comprimidos cuando están limitados por las velocidades de la red.
Elección del formato de archivo para cargar datos
Con soporte para una amplia variedad de formatos de archivo para la ingestión de datos, algunos son naturalmente más rápidos que otros. A continuación, se incluyen recomendaciones sobre los formatos de archivo al cargar datos en BigQuery:
- Al optimizar la velocidad de carga, se prefiere el formato de archivo Avro. Avro es un formato binario basado en filas que se puede dividir y leer en paralelo mediante múltiples ranuras, incluidos archivos comprimidos.
- Parquet y ORC son formatos binarios y de columnas. Al ingerir datos en BigQuery, es necesario leer todo el registro y, debido a que son formatos de columnas, tenderán a cargarse más lentamente que Avro.
- CSV y JSON comprimidos funcionarán más lentamente porque la compresión Gzip no se puede dividir y, por lo tanto, cada archivo comprimido debe descomprimirse antes de que el trabajo se pueda paralelizar.
La siguiente imagen clasifica los diferentes formatos según su rendimiento de carga

Métodos de carga
Al cargar datos en BigQuery, puede crear una tabla nueva o agregar o sobrescribir una tabla existente. Debe especificar el esquema de la tabla o la partición o, para los formatos de datos admitidos, puede utilizar la detección automática de esquemas.

BigQuery admite la carga de datos de varias fuentes en una variedad de formatos. Además de los servicios de Google, como Cloud Storage, BigQuery también admite la carga desde un almacenamiento externo como Amazon S3. Veamos las opciones para cargar estos archivos por lotes desde diferentes fuentes de datos.
Cargar con la IU de BigQuery
Como ha visto antes, también puede utilizar la misma interfaz de usuario web que se utiliza para examinar tablas y crear consultas para cargar datos. Una vez que tenga los datos disponibles para cargar en su máquina local o Cloud Storage, puede cargar datos en la tabla de destino usando la IU web. En la interfaz de usuario, puede habilitar la detección automática de esquemas o especificarlo explícitamente. Consulte la guía de inicio rápido para obtener más detalles.

Usando CLI - bq load
Para cargar datos en BigQuery mediante la CLI , puede usar el comando bq load. Por ejemplo, para importar un archivo CSV de Cloud Storage a BigQuery, especifique el URI de Cloud Storage o una lista separada por comas para varios URI que apuntan a los archivos CSV. La CLI admite las mismas opciones que vio en la interfaz de usuario web: la detección de esquema o la especificación manual de un esquema , la adición o sobrescritura y la ingestión de archivos desde su máquina local están disponibles.
bq load \
- source_format = CSV \
myproject.mydataset.mytable \
gs: //mybucket/mydata.csv \
./myschema.json
Cargar usando la API REST
La API REST se puede usar desde entornos de ejecución como Java o Python para comunicarse con BigQuery. El servicio recibe solicitudes HTTP y devuelve respuestas JSON. Tanto la IU web como la CLI usan esta API para comunicarse con BigQuery. Por ejemplo, eche un vistazo al uso de la API de Python para cargar datos en la tabla de BigQuery desde Cloud Storage:
Además de usar las herramientas anteriores, también tiene las siguientes opciones de canalización de datos para cargar datos en BigQuery:
Cloud Dataflow
- Dataflow es un servicio completamente administrado en GCP creado con la API de Apache Beam de código abierto con soporte para varias fuentes de datos : archivos, bases de datos, basados en mensajes y más. Con Dataflow, puede transformar y enriquecer los datos en los modos de transmisión por lotes y de transmisión con el mismo código. Google proporciona plantillas de Dataflow prediseñadas para trabajos por lotes.
Cloud Dataproc
- Dataproc es un servicio completamente administrado en GCP para los servicios Apache Spark y Apache Hadoop. Dataproc proporciona un conector de BigQuery que permite que las aplicaciones Spark y Hadoop procesen datos de BigQuery y escriban datos en BigQuery con su terminología nativa.
Registro en la nube
- Esta no es una opción de canalización de datos, pero Cloud Logging (anteriormente conocido como Stackdriver) brinda una opción para exportar archivos de registro a BigQuery. Consulta Exportar con el visor de registros para obtener más información y una guía de referencia sobre la exportación de registros a BigQuery para análisis de seguridad y acceso.
Entre bastidores
Detrás de escena, cuando BigQuery recibe una solicitud para cargar un archivo en su almacenamiento administrado, hace lo siguiente:
- Codificación, compresión y estadísticas: BigQuery codifica de manera óptima los datos después de analizar los tipos de datos, valora las frecuencias y comprime los datos de la manera más óptima para leer grandes cantidades de datos estructurados.
- Fragmentación: BigQuery distribuye los datos en fragmentos óptimos y, según cómo se define la tabla, carga los datos en particiones específicas, agrupa y vuelve a agrupar los datos.

- Cifrado: BigQuery siempre cifra los datos de forma predeterminada antes de que se escriban en el disco sin que usted deba realizar ninguna acción adicional. Los datos se descifran automáticamente cuando los lee un usuario autorizado. Para los datos en tránsito, sus datos se cifran dentro de los centros de datos de Google cuando se transfieren entre máquinas.
- Replicación geográfica: BigQuery replica automáticamente los datos en varios centros de datos según cómo hayas definido las ubicaciones de tu conjunto de datos : regional o multirregional.
Los usuarios de BigQuery obtienen el beneficio de las mejoras continuas en el rendimiento, la durabilidad, la eficiencia y la escalabilidad, sin tiempo de inactividad ni actualizaciones, ya que BigQuery optimiza continuamente su backend.
Puntos clave sobre los trabajos de carga de BigQuery
La ingesta por lotes es gratuita
- No hay ningún cargo por cargar datos en BigQuery con las opciones de ingesta por lotes mencionadas. Sin embargo, se aplican cuotas y límites .
El rendimiento de carga es el mejor esfuerzo
- Dado que el proceso utilizado para cargar datos está disponible desde un grupo compartido sin costo para el usuario, BigQuery no ofrece garantías sobre el rendimiento y la capacidad disponible de este grupo compartido. Esto se rige por el programador justo que asigna recursos entre trabajos de carga que pueden competir con cargas de otros usuarios o proyectos. Se han establecido cuotas para trabajos de carga para minimizar el impacto.
Sugerencia: Para garantizar la velocidad de ingestión de cualquier carga crítica, es posible que desee comprar ranuras dedicadas (reservas) y asignarles trabajos de canalización . Más sobre reservas en una futura publicación de blog.
Los trabajos de carga no consumen capacidad de consulta
- Los espacios que se utilizan para consultar datos son distintos de los que se utilizan para la ingestión. Por lo tanto, la ingestión de datos no afecta el rendimiento de las consultas.
Semántica ACID
- Para los datos cargados mediante el comando bq load, las consultas reflejarán la presencia de todos o ninguno de los datos. Las consultas nunca escanean datos parciales.
Transmisión de transmisión
La ingestión de transmisión admite casos de uso que requieren el análisis de grandes volúmenes de datos que llegan continuamente con paneles y consultas casi en tiempo real. El seguimiento de eventos de aplicaciones móviles es un ejemplo de este patrón. La aplicación en sí o los servidores que respaldan su backend podrían registrar las interacciones del usuario en un sistema de ingestión de eventos como Cloud Pub / Sub y transmitirlas a BigQuery mediante herramientas de canalización de datos como Cloud Dataflow o puedes ir sin servidor con Cloud Functions para eventos de bajo volumen. Luego, podría analizar estos datos para determinar tendencias generales, como áreas de alta interacción o problemas, y monitorear las condiciones de error en tiempo real.
La ingestión de transmisión de BigQuery te permite transmitir tus datos a BigQuery de un registro a la vez mediante el método tabledata.insertAll . La API permite inserciones no coordinadas de varios productores. Los datos ingeridos están disponibles de inmediato para consultar desde el búfer de transmisión unos segundos después de la primera inserción de transmisión. Sin embargo, es posible que los datos tarden hasta 90 minutos en estar disponibles para las operaciones de copia y exportación. Puede leer la publicación de nuestro blog sobre cómo funciona la inserción de transmisión y nuestros documentos para obtener más información.
Uno de los patrones comunes para ingerir datos en tiempo real en Google Cloud Platform es leer mensajes del tema de Cloud Pub / Sub mediante la canalización de Cloud Dataflow que se ejecuta en modo de transmisión y escribe en tablas de BigQuery después de que se realiza el procesamiento requerido. La mejor parte de la canalización de Cloud Dataflow es que también puede reutilizar el mismo código para el procesamiento por lotes y la transmisión, y Google administrará el trabajo de iniciar, ejecutar y detener los recursos informáticos para procesar su canalización en paralelo. Esta arquitectura de referencia cubre el caso de uso con mucho detalle.
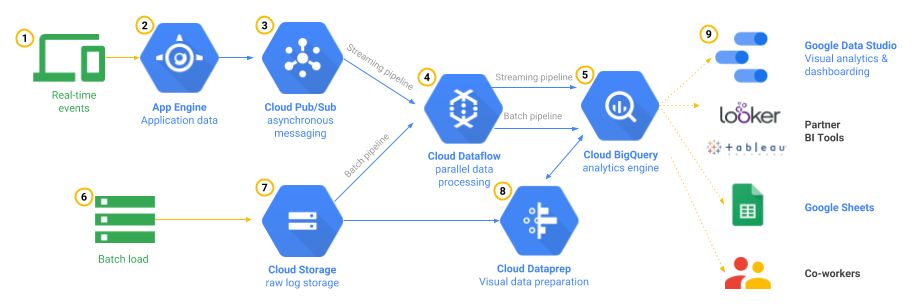
Tenga en cuenta que tiene opciones más allá de Cloud Dataflow para transmitir datos a BigQuery. Por ejemplo, puede escribir canalizaciones de transmisión en Apache Spark y ejecutar en un clúster de Hadoop como Cloud Dataproc con Apache Spark BigQuery Connector . También puede llamar a la API Streaming en cualquier biblioteca cliente para transmitir datos a BigQuery.
Servicio de transferencia de datos
El Servicio de transferencia de datos de BigQuery (DTS) es un servicio totalmente administrado para ingerir datos de aplicaciones de Google SaaS como Google Ads, proveedores de almacenamiento en la nube externos como Amazon S3 y transferir datos de tecnologías de almacenamiento de datos como Teradata y Amazon Redshift. DTS automatiza el movimiento de datos a BigQuery de forma programada y administrada. DTS se puede utilizar para reabastecimiento de datos para recuperarse de interrupciones o brechas.
Piense en el Servicio de transferencia de datos como un servicio de entrega de datos sin esfuerzo para importar datos de aplicaciones a BigQuery.
Materialización de consultas
Cuando ejecuta consultas en BigQuery, sus conjuntos de resultados se pueden materializar para crear nuevas tablas. Hemos visto este patrón en la publicación anterior sobre particiones y clústeres, donde creamos nuevas tablas a partir de los resultados de las consultas en el conjunto de datos públicos de Stack Overflow.
La materialización de los resultados de las consultas es una excelente manera de simplificar los patrones ETL (Extraer, Transformar y Cargar) o ELT (Extraer, Cargar y Transformar) en BigQuery. Por ejemplo, al realizar un trabajo exploratorio o la creación de prototipos en archivos almacenados en Cloud Storage mediante consultas federadas en BigQuery , puede conservar esos resultados de análisis en BigQuery para obtener información valiosa. Tenga en cuenta que se le cobra por la cantidad de bytes leídos por la consulta y la cantidad de bytes almacenados en el almacenamiento de BigQuery después de que se escriben las tablas.
Consultar sin cargar datos
Como se mencionó al comienzo de esta publicación, no es necesario que cargue datos en BigQuery antes de ejecutar consultas en las siguientes situaciones:
- Conjuntos de datos públicos : los conjuntos de datos públicos son conjuntos de datos almacenados en BigQuery y compartidos con el público. Para obtener más información, consulte Conjuntos de datos públicos de BigQuery .
- Conjuntos de datos compartidos: puedes compartir conjuntos de datos almacenados en BigQuery. Si alguien ha compartido un conjunto de datos con usted, puede ejecutar consultas en ese conjunto de datos sin cargar los datos.
- Fuentes de datos externas (federadas): puede omitir el proceso de carga de datos creando una tabla basada en una fuente de datos externa .
Integraciones de socios
Además de las soluciones disponibles de forma nativa en BigQuery, también puede verificar las opciones de integración de datos de los socios de Google Cloud que han integrado sus herramientas líderes en la industria con BigQuery.
¿Qué sigue?
En este artículo, aprendimos diferentes formas de introducir datos en BigQuery según su caso de uso. Específicamente, nos sumergimos en la ingesta de fuentes y formatos de datos por lotes en BigQuery con un vistazo a la ingestión de transmisión, el servicio de transferencia de datos y la consulta de fuentes de datos externas sin cargar datos en BigQuery.
- Vea el video sobre cómo cargar datos CSV en lotes y analizar datos en BigQuery.
- Obtenga más información sobre cómo cargar datos en BigQuery.
- Pruebe este laboratorio de código para transferir archivos de Google Cloud Storage a BigQuery en su BigQuery Sandbox
En la próxima publicación, analizaremos la consulta de datos en BigQuery y el diseño de esquemas. En las próximas publicaciones, profundizaremos en otros mecanismos de ingestión: el servicio de transferencia de datos y transmisión.
Manténganse al tanto. ¡Gracias por leer! ¿Tienes alguna pregunta o quieres charlar? Encuéntrame en Twitter o LinkedIn .
Gracias a Yuri Grinshsteyn y Alicia Williams por ayudarnos con la publicación.
Explicación de BigQuery: la ingesta de datos se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación destacando y respondiendo a esta historia.