En la publicación anterior de la serie BigQuery Explained , analizamos la consulta de conjuntos de datos en BigQuery mediante SQL, cómo guardar y compartir consultas, un vistazo a la administración de vistas estándar y materializadas. En esta publicación, nos centraremos en las uniones y la desnormalización de datos con campos anidados y repetidos. ¡Vamos a sumergirnos en él!
Uniones
Por lo general, los esquemas de almacenamiento de datos siguen un esquema de estrella o copo de nieve , donde una tabla de "hechos" centralizada que contiene eventos está rodeada por tablas satélite llamadas "dimensiones" con los atributos descriptivos relacionados con la tabla de hechos. Las tablas de hechos están desnormalizadas y las tablas de dimensiones están normalizadas . El esquema en estrella admite consultas analíticas en un almacén de datos, lo que permite ejecutar consultas más simples ya que el número de uniones es limitado, realizar agregaciones más rápidas y mejorar el rendimiento de las consultas.
Esto contrasta con un sistema de procesamiento transaccional en línea (OLTP), donde el esquema está altamente normalizado y las uniones se realizan ampliamente para obtener los resultados. La mayoría de las consultas analíticas en un almacén de datos aún requieren realizar la operación JOIN para combinar datos de hechos con atributos de dimensión o con otra tabla de hechos.
Veamos cómo funcionan las uniones en BigQuery. BigQuery admite tipos de unión ANSI SQL. Las operaciones JOIN se realizan en dos elementos según las condiciones de combinación y el tipo de combinación . Los elementos de la operación JOIN pueden ser tablas, subconsultas , declaraciones WITH o ARRAY de BigQuery (una lista ordenada con cero o más valores del mismo tipo de datos).
BigQuery admite los siguientes tipos de combinación :
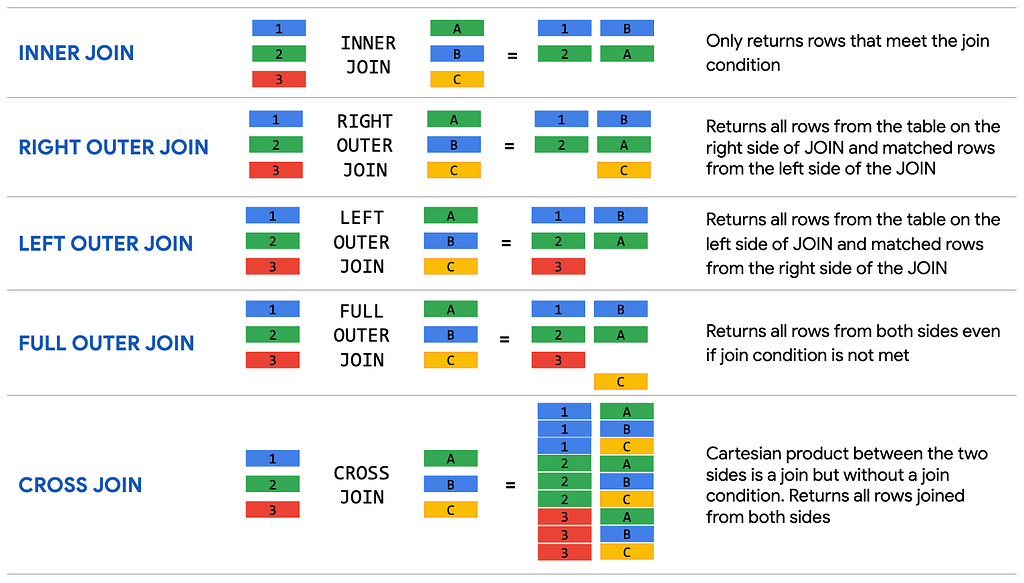
Veamos un ejemplo de esquema de almacén de datos para una tienda minorista que se muestra a continuación. La tabla de datos original con las transacciones minoristas en la parte superior se traduce a un esquema de almacén de datos con los detalles del pedido almacenados en una tabla de hechos de Transacciones e información de Producto y Cliente como tablas de dimensiones.

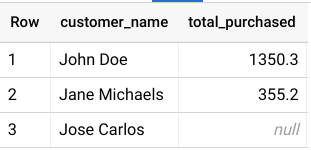
Para saber cuánto ha gastado cada cliente en un mes determinado, debe realizar una tabla de hechos OUTER JOIN between Transactions con la tabla de dimensiones de Customer para obtener los resultados. Generaremos transacciones de muestra y datos de clientes sobre la marcha utilizando la cláusula WITH y veremos el JOIN en acción. Ejecute la siguiente consulta:
El uso de la cláusula WITH permite nombrar una subconsulta y usarla en consultas posteriores, como la instrucción SELECT aquí (también llamada Expresiones de tabla comunes ). Utilizamos RIGHT OUTER JOIN entre Cliente y Transacciones para obtener una lista de todos los clientes con su gasto total.
Nota : La cláusula WITH se utiliza principalmente para facilitar la lectura porque no se materializan. Si una consulta aparece en más de una cláusula WITH, se ejecuta en cada cláusula.
Optimización de patrones de unión
Broadcast se une
- Al unir una tabla grande a una pequeña, BigQuery crea una unión de transmisión en la que la tabla pequeña se envía a cada espacio que procesa la tabla grande.
- Aunque el optimizador de consultas SQL puede determinar qué tabla debe estar en qué lado de la combinación, se recomienda ordenar las tablas unidas de manera adecuada. La mejor práctica es colocar primero la tabla más grande, seguida de la más pequeña y luego disminuir el tamaño.
Hash se une
- Al unir dos tablas grandes, BigQuery usa operaciones hash y shuffle para mezclar las tablas izquierda y derecha de modo que las claves coincidentes terminen en la misma ranura para realizar una combinación local. Esta es una operación costosa ya que es necesario mover los datos.
- En algunos casos, la agrupación en clústeres puede acelerar las combinaciones hash. Como se mencionó en la publicación anterior , la agrupación en clústeres tiende a colocar datos en los mismos archivos en columnas, lo que mejora la eficiencia general de la mezcla de datos, particularmente si hay alguna parte de agregación previa del plan de ejecución de consultas.
Uno mismo se une
- En una autocombinación, una tabla se une a sí misma. Normalmente, se trata de un antipatrón de SQL que puede ser una operación costosa para tablas grandes y puede requerir obtener datos en más de una pasada.
- En su lugar, se recomienda evitar las autouniones y, en cambio, utilizar funciones analíticas (ventana) para reducir los bytes generados por la consulta.
Uniones cruzadas
- Las combinaciones cruzadas son un antipatrón de SQL y pueden causar problemas de rendimiento importantes, ya que generan datos de salida más grandes que las entradas y, en algunos casos, es posible que las consultas nunca finalicen.
- Para evitar problemas de rendimiento con las combinaciones cruzadas, utilice funciones de agregación para agregar previamente los datos o utilice funciones analíticas que suelen ser más eficaces que una combinación cruzada.
Uniones sesgadas
- La desviación de datos puede ocurrir cuando los datos de la tabla se dividen en particiones de tamaño desigual. Al unir tablas grandes que requieren la reorganización de datos, el sesgo puede provocar un desequilibrio extremo en la cantidad de datos enviados entre las ranuras.
- Para evitar problemas de rendimiento asociados con uniones sesgadas (o uniones no balanceadas), prefiltre los datos de la tabla lo antes posible o divida la consulta en dos o más consultas, si es posible.
Consulte la documentación de prácticas recomendadas de BigQuery para obtener más recomendaciones de este tipo para optimizar el rendimiento de su consulta.
Desnormalizar datos con estructuras anidadas y repetidas
Al realizar operaciones analíticas en esquemas parcialmente normalizados, como el esquema de estrella o de copo de nieve en un almacén de datos, se deben unir varias tablas para realizar las agregaciones necesarias. Sin embargo, las JOIN no suelen ser tan eficaces como las estructuras desnormalizadas. El rendimiento de las consultas muestra un deterioro mucho más pronunciado en presencia de JOIN.
El método convencional de desnormalización de datos implica escribir un hecho, junto con todas sus dimensiones, en una estructura plana. Por el contrario, el método preferido para desnormalizar datos aprovecha la compatibilidad nativa de BigQuery con estructuras anidadas y repetidas en datos de entrada JSON o Avro. La expresión de registros mediante estructuras anidadas y repetidas puede proporcionar una representación más natural de los datos subyacentes.
Continuando con el mismo esquema de almacenamiento de datos para una tienda minorista, los siguientes son los aspectos clave a tener en cuenta:
- Un pedido en las Transacciones pertenece a un solo Cliente y
- Un pedido en las Transacciones puede tener varios Productos (o artículos).
Anteriormente, vimos este esquema organizado en varias tablas. Una alternativa es organizar toda la información en una sola tabla usando campos anidados y repetidos.
Una cartilla de campos anidados y repetidos
BigQuery admite la carga de datos anidados y repetidos desde formatos de origen que admiten esquemas basados en objetos, como archivos de exportación JSON, Avro, Firestore y Datastore. ARRAY y STRUCT o RECORD son tipos de datos complejos para representar campos anidados y repetidos.
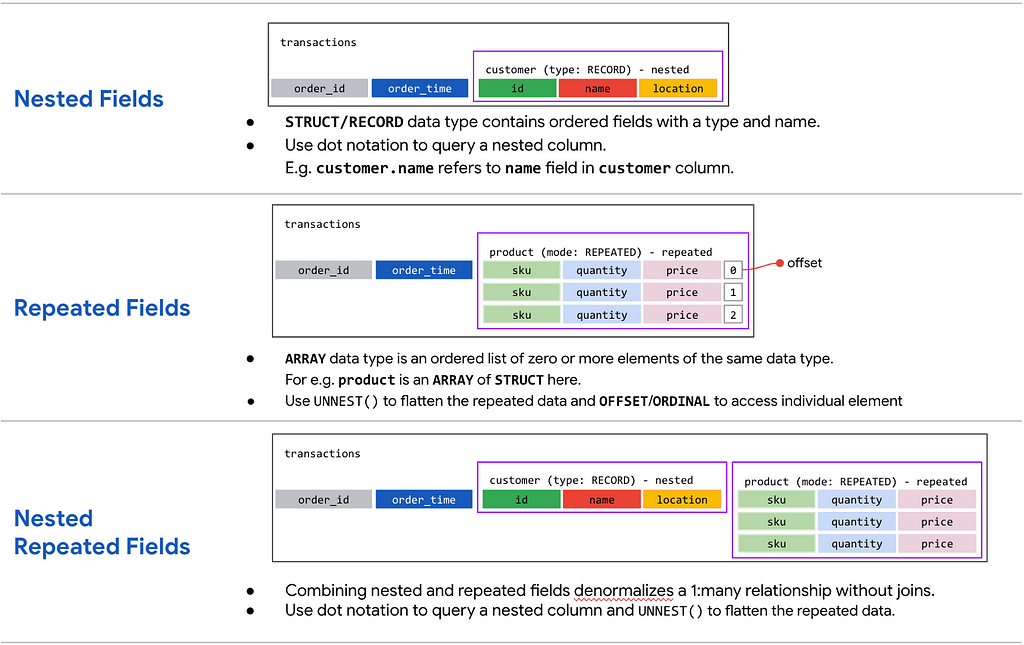
Campos anidados
- UNA ESTRUCTURA o REGISTRO contiene campos ordenados, cada uno con un tipo y nombre de campo. Puede definir una o más de las columnas secundarias como tipos STRUCT, denominados STRUCT anidados ( hasta 15 niveles de anidamiento ).
- Tomemos las transacciones y los datos del cliente en una estructura anidada. Tenga en cuenta que un pedido en las Transacciones pertenece a un solo Cliente. Esto se puede representar como esquema a continuación:
[
{"name": "id", "type": "INTEGER", "mode": "REQUIRED"},
{"name": "time", "type": "TIMESTAMP", "mode": "REQUIRED"},
{"nombre": "cliente", "tipo": " REGISTRO ", "campos":
[
{"name": "id", "type": "INTEGER", "mode": "REQUIRED"},
{"name": "name", "type": "STRING", "mode": "REQUIRED"},
{"nombre": "ubicación", "tipo": "STRING"}
]
}
]
- Observe que la columna del cliente es de tipo REGISTRO con los campos ordenados anidados dentro del esquema principal junto con los campos de Transacciones: id y hora.
- BigQuery aplana automáticamente los campos anidados al realizar consultas. Para consultar una columna con datos anidados, cada campo debe identificarse en el contexto de la columna que lo contiene. Por ejemplo: customer.id se refiere al campo id en la columna del cliente.

Campos repetidos
- Un ARRAY es una lista ordenada de cero o más elementos del mismo tipo de datos. No se admite una matriz de matrices. Un campo repetido agrega una matriz de datos dentro de un solo campo o RECORD.
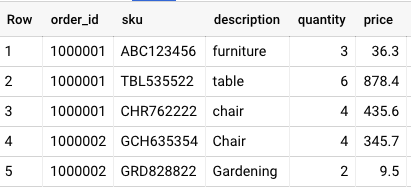
- Consideremos las transacciones y los datos del producto. Un pedido en las Transacciones puede tener varios Productos (o artículos). Al especificar la columna Producto como campo repetido en el esquema, definiría el modo de la columna de producto como REPETIDO . El esquema con campo repetido se muestra a continuación:
[
{"name": "id", "type": "INTEGER", "mode": "REQUIRED"},
{"name": "time", "type": "TIMESTAMP", "mode": "REQUIRED"},
{"nombre": "producto", "tipo": "REGISTRO", "modo": " REPETIDO ", "campos":
[
{"name": "sku", "type": "STRING", "mode": "REQUIRED"},
{"nombre": "descripción", "tipo": "STRING"},
{"nombre": "cantidad", "tipo": "INTEGER"},
{"name": "price", "type": "FLOAT", "mode": "REQUIRED"}
]
}
]
- Cada entrada en un campo repetido es un ARRAY. Por ejemplo, cada artículo en la columna de producto para un pedido es de tipo ESTRUCTURA o REGISTRO con campos de código, descripción, cantidad y precio.
- BigQuery agrupa automáticamente los datos por "filas" al consultar uno o más campos repetidos.
- Para aplanar los datos repetidos (y agrupados), utilizará la función UNNEST () con el nombre de la columna repetida. Puede usar la función UNNEST solo dentro de la cláusula FROM o el operador IN .
Leer más sobre el manejo de ARRAY y STRUCT s s aquí .
Esquema desnormalizado con campos repetidos anidados
Pongamos todo junto y veamos una representación alternativa del esquema de Transacciones que combina elementos anidados y repetidos con información de Cliente y Producto en una sola tabla. El esquema se representa de la siguiente manera:
[
{"name": "id", "type": "INTEGER", "mode": "REQUIRED"},
{"name": "time", "type": "TIMESTAMP", "mode": "REQUIRED"},
{"nombre": "cliente", "tipo": " REGISTRO ", "campos":
[
{"name": "id", "type": "INTEGER", "mode": "REQUIRED"},
{"name": "name", "type": "STRING", "mode": "REQUIRED"},
{"nombre": "ubicación", "tipo": "STRING"}
]
},
{"nombre": "producto", "tipo": "REGISTRO", "modo": " REPETIDO ", "campos":
[
{"name": "sku", "type": "STRING", "mode": "REQUIRED"},
{"nombre": "descripción", "tipo": "STRING"},
{"nombre": "cantidad", "tipo": "INTEGER"},
{"name": "price", "type": "FLOAT", "mode": "REQUIRED"}
]
}
]

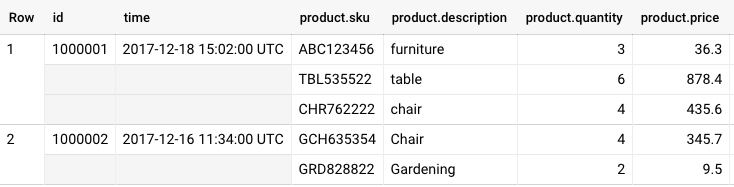
En la tabla Transacciones , la parte exterior contiene el pedido y la información del cliente , y la parte interior contiene los elementos de línea del pedido , que se representan como elementos repetidos anidados. Expresar registros mediante el uso de campos anidados y repetidos simplifica la carga de datos mediante archivos JSON o Avro . Después de haber creado dicho esquema, puede realizar las operaciones SELECT, INSERT, UPDATE y DELETE en cualquier campo individual utilizando una notación de puntos, por ejemplo, Order.sku.
Una vez más, generaremos los datos de las transacciones sobre la marcha y ejecutaremos esta consulta en el esquema de Transacciones con campos anidados y repetidos para encontrar las compras totales en el pedido junto con el nombre del cliente.
Analicemos esta consulta y entendamos cómo se desnormalizan los datos.
Representación de datos desnormalizados
- Los datos de la transacción se generan utilizando una declaración WITH , y cada fila consta de información del pedido , información del cliente y un campo anidado que contiene artículos individuales que se representan como una ARRAY de STRUCT que representan: sku, cantidad y precio.
- Al usar ARRAY of STRUCTs, obtenemos una ventaja de rendimiento significativa al evitar los JOIN de tabla. ARRAY of STRUCTs se puede tratar como tablas preunidas que conservan la estructura de los datos. Los elementos individuales de los registros anidados se pueden recuperar solo cuando sea necesario. También existe el beneficio adicional de tener todo el contexto empresarial en una tabla, en lugar de administrar las claves JOIN y las tablas asociadas.
Normalizar datos para analizar
- En la consulta SELECT, leemos campos como el precio del registro anidado usando la función UNNEST () y la notación de puntos. Por ejemplo orders.price
- UNNEST () ayuda a traer los elementos de la matriz nuevamente a las filas
- UNNEST () siempre sigue el nombre de la tabla en la cláusula FROM (conceptualmente como una tabla unida previamente)
Al ejecutar la consulta anterior, se obtienen resultados con el pedido, el cliente y el monto total del pedido.

Directrices para diseñar un esquema desnormalizado
A continuación, se incluyen las pautas generales para diseñar un esquema desnormalizado en BigQuery:
- Desnormalice una tabla de dimensiones de más de 10 GB, a menos que haya pruebas sólidas de que los costos de la manipulación de datos, como las operaciones UPDATE y DELETE, superan los beneficios de las consultas óptimas.
- Mantenga una tabla de dimensiones normalizada de menos de 10 GB, a menos que la tabla rara vez pase por las operaciones UPDATE y DELETE.
- Aproveche al máximo los campos anidados y repetidos en tablas desnormalizadas.
Consulte este artículo para obtener más información sobre la desnormalización y el diseño de esquemas en un almacén de datos.
¿Qué sigue?
En esta publicación, trabajamos con combinaciones, revisamos la optimización de patrones de combinación y datos desnormalizados con campos anidados y repetidos.
- Trabajar con JOIN en BigQuery
- Trabajar con funciones analíticas (ventana) en BigQuery
- Trabajar con datos anidados y repetidos en BigQuery [ Video ] [ Docs ]
- Prácticas recomendadas de BigQuery para el rendimiento de las consultas, incluidas las uniones y más
- Consultar un conjunto de datos públicos en BigQuery con campos anidados y repetidos en su zona de pruebas de BigQuery : ¡ gracias a Evan Jones por la demostración ! (¡ Codelab próximamente! )
En la próxima publicación, veremos la manipulación de datos en BigQuery junto con secuencias de comandos, procedimientos almacenados y más.
Manténganse al tanto. ¡Gracias por leer! ¿Tienes alguna pregunta o quieres charlar? Encuéntrame en Twitter o LinkedIn .
Gracias a Alicia Williams por ayudar con la publicación.
Explicación de BigQuery: Trabajar con uniones, datos anidados y repetidos se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación destacando y respondiendo a esta historia.