Anteriormente, en BigQuery Explained, revisamos la arquitectura de BigQuery , la administración del almacenamiento y la ingesta de datos en BigQuery . En esta publicación, cubriremos la consulta de conjuntos de datos en BigQuery usando SQL , guardar y compartir consultas, crear vistas y vistas materializadas. ¡Empecemos!
SQL estándar
BigQuery admite dos dialectos de SQL: SQL estándar y SQL heredado . Se prefiere SQL estándar para consultar datos almacenados en BigQuery porque cumple con el estándar ANSI SQL 2011. Tiene otras ventajas sobre el SQL heredado, como la inserción automática de predicados para las operaciones JOIN y la compatibilidad con subconsultas correlacionadas. Consulte Aspectos destacados de SQL estándar para obtener más información.
Cuando ejecutas una consulta SQL en BigQuery, automáticamente crea, programa y ejecuta un trabajo de consulta. BigQuery ejecuta trabajos de consulta en dos modos: interactivo (predeterminado) y por lotes .
- Las consultas interactivas (bajo demanda) se ejecutan lo antes posible y estas consultas cuentan para el límite de frecuencia simultánea y el límite diario .
- Las consultas por lotes se ponen en cola y se inician tan pronto como los recursos inactivos están disponibles en el grupo de recursos compartidos de BigQuery, lo que generalmente ocurre en unos pocos minutos. Si BigQuery no ha iniciado la consulta en 24 horas, la prioridad del trabajo se cambia a interactiva. Las consultas por lotes no cuentan para su límite de frecuencia simultánea. Utilizan los mismos recursos que las consultas interactivas.
Las consultas en esta publicación siguen el dialecto SQL estándar y se ejecutan en modo interactivo, a menos que se indique lo contrario.
Tipos de tablas de BigQuery
Cada tabla en BigQuery se define mediante un esquema que describe los nombres de las columnas, los tipos de datos y otros metadatos. BigQuery admite los siguientes tipos de tablas:
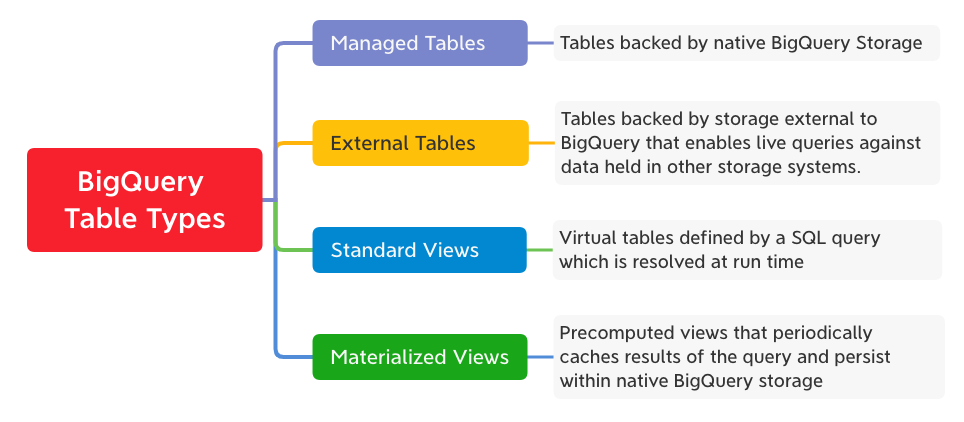
Esquemas de BigQuery
En BigQuery, los esquemas se definen a nivel de tabla y proporcionan estructura a los datos. El esquema describe las definiciones de columna con su nombre, tipo de datos, descripción y modo.
- Los tipos de datos pueden ser tipos de datos simples, como enteros, o más complejos, como ARRAY y STRUCT para valores anidados y repetidos.
- Los modos de columna pueden ser NULABLES, REQUERIDOS o REPETIDOS.
El esquema de tabla se especifica al cargar datos en la tabla o al crear una tabla vacía. Alternativamente, al cargar datos, puede usar la detección automática de esquemas para formatos de datos de origen de autodescripción , como archivos de exportación de Avro, Parquet, ORC, Cloud Firestore o Cloud Datastore. El esquema se puede definir manualmente o en un archivo JSON como se muestra.
[
{
"descripción": "[DESCRIPCIÓN]",
"nombre nombre]",
"tipo": "[TIPO]",
"modo": "[MODO]"
},
{
"descripción": "[DESCRIPCIÓN]",
"nombre nombre]",
"tipo": "[TIPO]",
"modo": "[MODO]"
}
]
Usar SQL para análisis
Ahora analicemos uno de los conjuntos de datos públicos de BigQuery relacionados con los juegos y los jugadores de baloncesto de la NCAA que usan SQL. Los datos del juego cubren jugada por jugada y puntajes de caja que se remontan a 2009. Veremos un juego específico de la temporada 2014 entre los Wildcats de Kentucky y los Fighting Irish de Notre Dame. Este juego tuvo un final emocionante. ¡Averigüemos qué lo hizo emocionante!
En su zona de pruebas de BigQuery , abra el conjunto de datos de baloncesto de la NCAA desde conjuntos de datos públicos. Haga clic en el botón "VER CONJUNTO DE DATOS" para abrir el conjunto de datos en la IU web de BigQuery.
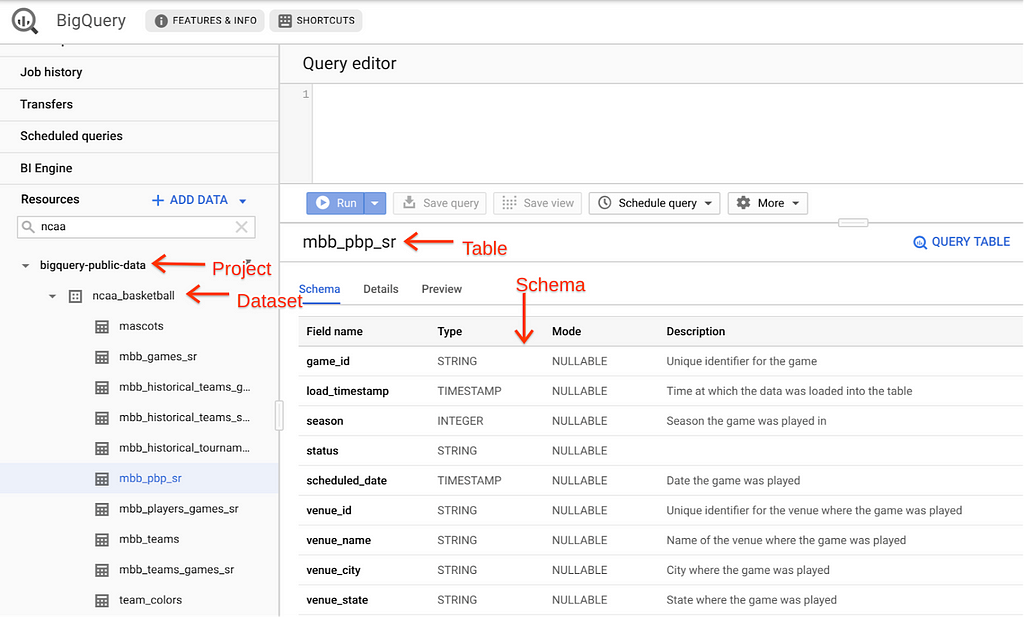
Navegue a la tabla mbb_pbp_sr en el conjunto de datos ncaa_basketball para ver el esquema. Esta tabla tiene información jugada por jugada de todos los juegos de baloncesto masculino en la temporada 2013–2014, y cada fila de la tabla representa un solo evento en un juego.
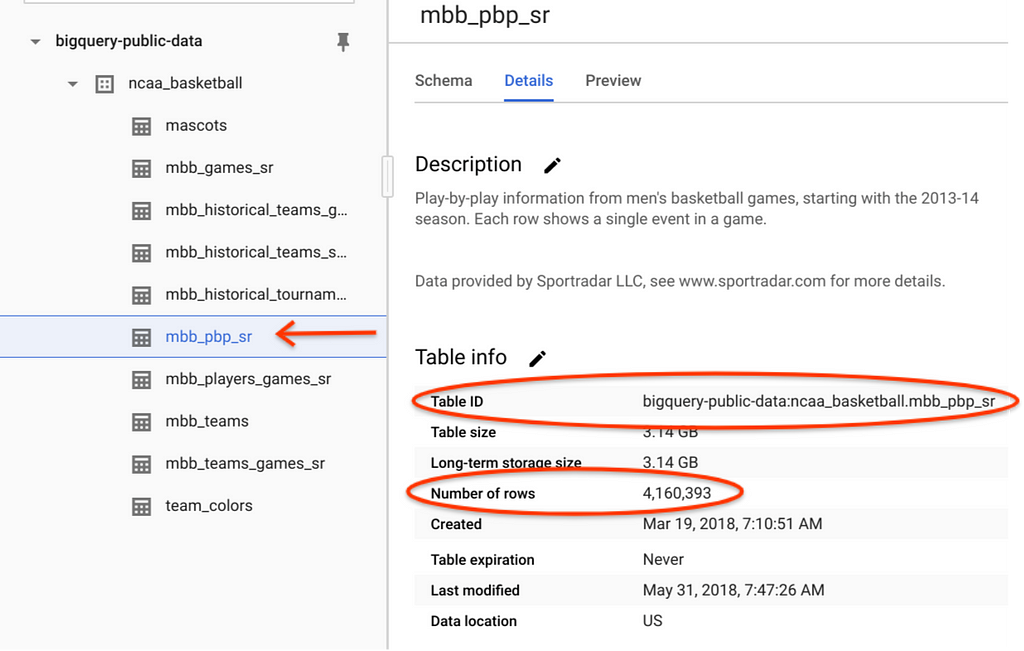
Consulte la sección Detalles de la tabla mbb_pbp_sr . Hay ~ 4 millones de eventos de juegos con un volumen total de ~ 3GB.
Ejecutemos una consulta para filtrar los eventos del juego que nos interesa. La consulta selecciona las siguientes columnas de la tabla mbb_pbp_sr :
- game_clock: tiempo restante del juego antes del final
- points_scored: se anotaron puntos en un evento
- team_name: nombre del equipo que anotó los puntos
- event_description: Descripción del evento
- timestamp: Hora en que ocurrió el evento
Un desglose de lo que está haciendo esta consulta:
- La sentencia SELECT recupera las filas y las columnas especificadas de la tabla
- La cláusula WHERE filtra las filas devueltas por SELECT. Esta consulta se filtra para devolver filas para el juego específico que nos interesa.
- La instrucción ORDER BY controla el orden de las filas en el conjunto de resultados. Esta consulta ordena las filas resultantes de SELECT por marca de tiempo en orden descendente.
- Finalmente, LIMIT restringe la cantidad de datos devueltos por la consulta. Esta consulta devuelve 10 eventos del conjunto de resultados después de ordenar las filas. Tenga en cuenta que agregar LIMIT no reduce la cantidad de datos procesados por el motor de consultas.
Ahora veamos los resultados.
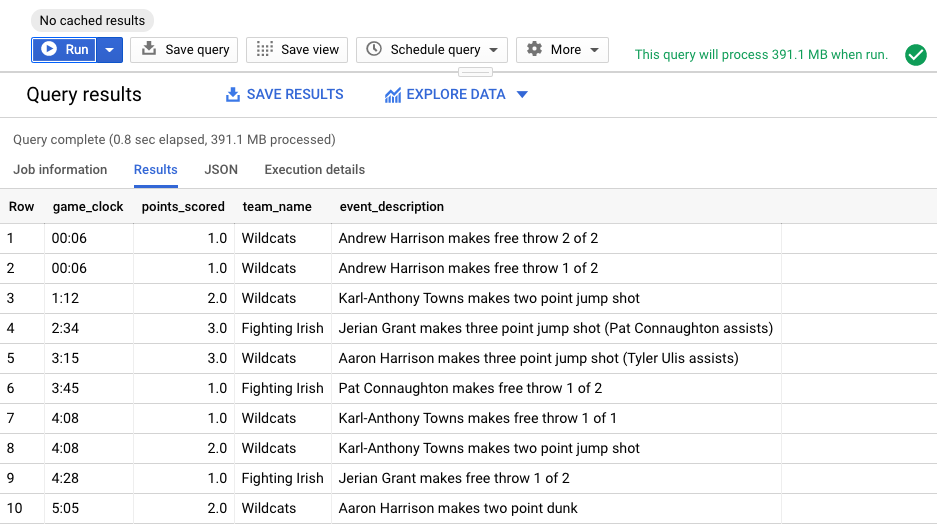
De los resultados, parece que el jugador Andrew Harrison hizo dos tiros libres anotando 2 puntos con solo 6 segundos restantes en el juego. Esto no nos dice mucho, excepto que se anotaron puntos hacia el final del juego.
Consejo: Evite utilizar SELECT * en la consulta. En su lugar, consulte solo las columnas necesarias. Para excluir solo ciertas columnas, use SELECT * EXCEPT .
Modifiquemos la consulta para incluir la suma acumulada de puntuaciones de cada equipo hasta la hora del evento, utilizando funciones analíticas (ventana) . Las funciones analíticas calculan agregados para cada fila sobre un grupo de filas definido por una ventana, mientras que las funciones agregadas calculan un valor agregado único sobre un grupo de filas.
Ejecute la siguiente consulta con dos nuevas columnas agregadas: wildcats_score y fighting_irish_score , calculadas sobre la marcha utilizando la columna points_scored .
Un desglose de lo que está haciendo esta consulta:
- Calcule la SUMA acumulada de puntajes de cada equipo en el juego, especificada por la declaración CASE
- SUM se calcula sobre las puntuaciones en la ventana definida en la cláusula OVER
- La cláusula OVER hace referencia a una ventana (grupo de filas) para usar SUM
- ORDER BY es parte de la especificación de la ventana que define el orden de clasificación dentro de una partición. Esta consulta ordena las filas por marca de tiempo
- Defina el marco de la ventana desde el inicio del juego especificado por UNBOUNDED ANTES de la FILA ACTUAL sobre la que se evalúa la función analítica SUM ().
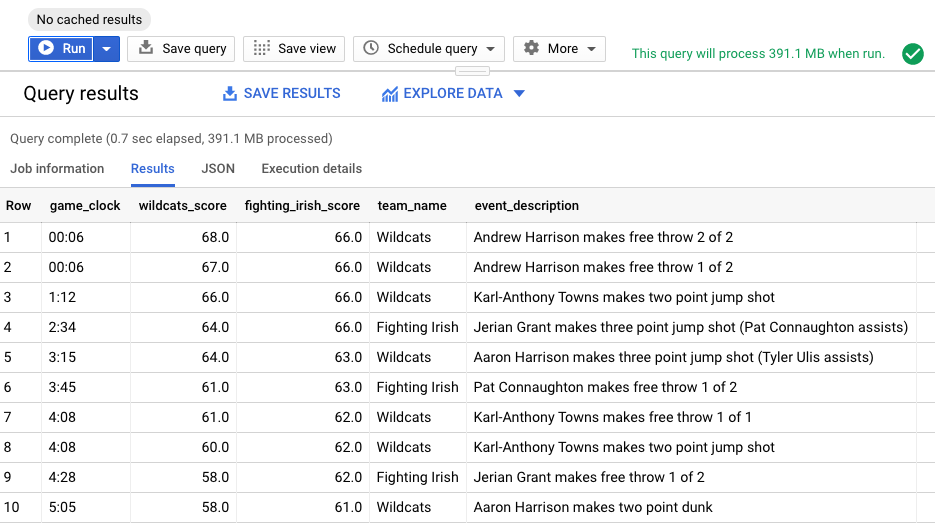
De los resultados, podemos ver cómo terminó el juego. El Fighting Irish mantuvo la ventaja por cuatro puntos con 04:28 minutos para el final. Karl-Anthony Towns of Wildcats pudo empatar el juego en una bandeja con 01:12 minutos restantes, y Andrew Harrison hizo dos tiros libres con 00:06 segundos restantes, preparando el escenario para la victoria de los Wildcats. ¡Ese fue un acabado de morderse las uñas!
Además de las funciones agregadas y analíticas, BigQuery también admite funciones y operadores como manipulación de cadenas, fecha / hora, funciones matemáticas, extracción JSON y más, como se muestra.
Consulte la referencia de la función SQL de BigQuery para obtener la lista completa. En las próximas publicaciones, cubriremos otras funciones de consulta avanzadas en BigQuery, como funciones definidas por el usuario, funciones espaciales y más.
La vida de una consulta SQL de BigQuery
Debajo del capó, cuando ejecuta la consulta SQL, hace lo siguiente:
- Se envía un QueryJob al servicio de BigQuery. Como se revisó en la arquitectura de BigQuery , el procesamiento de BigQuery está desacoplado del almacenamiento de BigQuery y están diseñados para trabajar juntos a fin de organizar los datos y hacer que las consultas sean eficientes en grandes conjuntos de datos.
- Cada consulta ejecutada se divide en etapas que luego son procesadas por los trabajadores (ranuras) y escritas nuevamente en Shuffle. Shuffle proporciona resistencia a fallas dentro de los propios trabajadores, digamos que un trabajador tendría un problema durante el procesamiento de consultas.
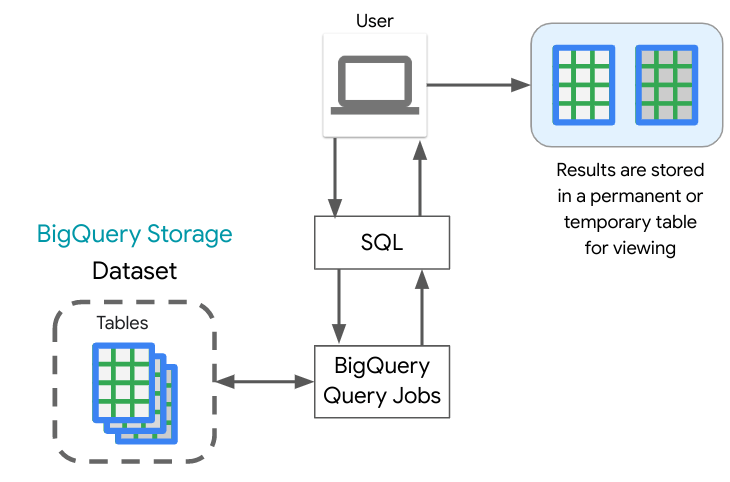
- El motor de BigQuery utiliza el formato de almacenamiento en columnas de BigQuery para escanear solo las columnas necesarias para ejecutar la consulta. Una de las mejores prácticas para controlar los costos es consultar solo las columnas que necesita .
- Una vez que se completa la ejecución de la consulta, el servicio de consultas conserva los resultados en una tabla temporal y la interfaz de usuario web muestra esos datos. También puede solicitar escribir los resultados en una tabla permanente.
Guardar y compartir consultas
Guardar consultas
Ahora que ha ejecutado consultas SQL para realizar análisis, ¿cómo guardaría esos resultados? BigQuery escribe todos los resultados de la consulta en una tabla. El usuario identifica explícitamente la tabla como una tabla de destino o una tabla de resultados temporal almacenada en caché. Esta tabla temporal se almacena durante 24 horas, por lo que si vuelve a ejecutar exactamente la misma consulta (coincidencia exacta de la cadena) y los resultados no serían diferentes, BigQuery simplemente devolverá un puntero a los resultados almacenados en caché. Las consultas que se pueden atender desde la caché no incurren en ningún cargo. Consulte la documentación para comprender las limitaciones y excepciones del almacenamiento en caché de consultas.
Puede ver los resultados de las consultas en caché desde la pestaña Historial de consultas en la IU de BigQuery. Este historial incluye todas las consultas enviadas por usted al servicio, no solo las enviadas a través de la interfaz de usuario web.
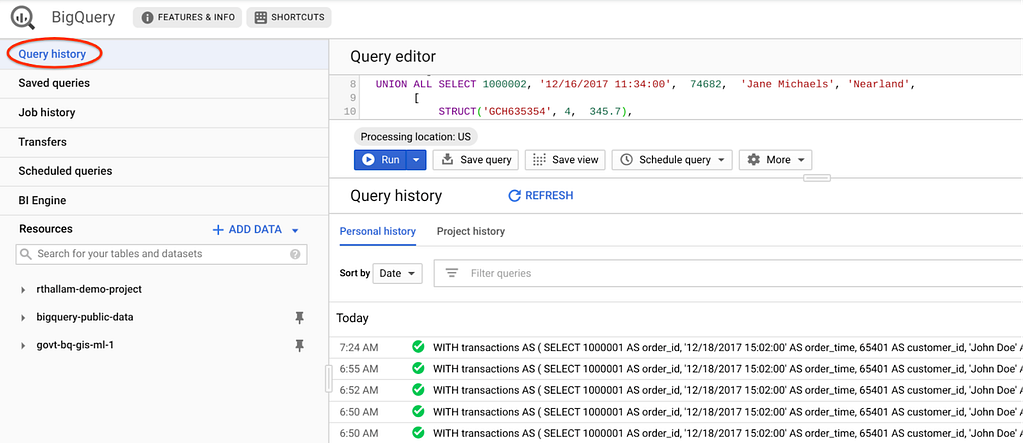
Puede deshabilitar la recuperación de los resultados almacenados en caché desde la configuración de la consulta al ejecutar la consulta. Esto requiere que BigQuery calcule el resultado de la consulta, lo que generará cargos por la ejecución de la consulta. Esto se usa generalmente en escenarios de evaluación comparativa, como en la publicación anterior que compara el rendimiento de tablas particionadas y agrupadas con tablas no particionadas.
También puede solicitar que la consulta se escriba en una tabla de destino . Tendrás control sobre cuándo se elimina la tabla. Debido a que la tabla de destino es permanente, se le cobrará por el almacenamiento de los resultados.
Compartir consultas
BigQuery te permite compartir consultas con otras personas. Cuando guarda una consulta, puede ser privada (visible solo para usted), compartida a nivel de proyecto (visible para los miembros del proyecto) o pública (cualquiera puede verla).
Vea este video para saber cómo guardar y compartir sus consultas en BigQuery.
Vistas estándar
Una vista es una tabla virtual definida por una consulta SQL. Una vista tiene propiedades similares a una tabla y se puede consultar como una tabla. El esquema de la vista es el esquema que resulta de ejecutar la consulta. Los resultados de la consulta de la vista contienen datos solo de las tablas y campos especificados en la consulta que define la vista.
Puede crear una vista guardando la consulta desde la IU de BigQuery con el botón "Guardar vista" o usando BigQuery DDL - declaración CREATE VIEW . Guardar una consulta como una vista no conserva los resultados aparte del almacenamiento en caché en una tabla temporal, que caduca dentro de una ventana de 24 horas. El comportamiento es similar a la consulta ejecutada en las tablas.
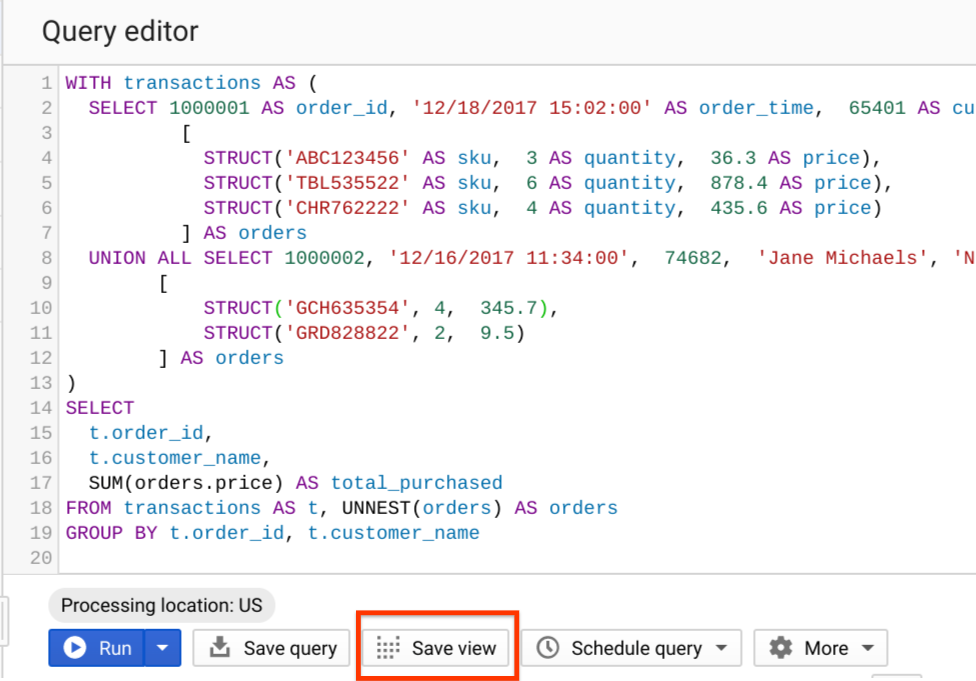
¿Cuándo usar vistas estándar?
- Supongamos que desea exponer consultas con lógica compleja a sus usuarios y desea evitar que los usuarios necesiten recordar la lógica, entonces puede convertir esas consultas en una vista.
- Otro caso de uso es que las vistas se pueden colocar en conjuntos de datos y ofrecen controles de acceso detallados para compartir conjuntos de datos con usuarios y grupos específicos sin darles acceso a tablas subyacentes. Estas vistas se denominan vistas autorizadas . Examinaremos la protección y el acceso a conjuntos de datos en detalle en una publicación futura.
Consulte la documentación de BigQuery para crear y administrar vistas estándar.
Vistas materializadas
BigQuery admite vistas materializadas (MV), una función beta . MV son vistas precalculadas que periódicamente almacenan en caché los resultados de una consulta para aumentar el rendimiento y la eficiencia. Las consultas que utilizan MV son generalmente más rápidas y consumen menos recursos que las consultas que recuperan los mismos datos solo de la tabla base. Pueden mejorar significativamente el rendimiento de las cargas de trabajo con consultas comunes y repetidas.
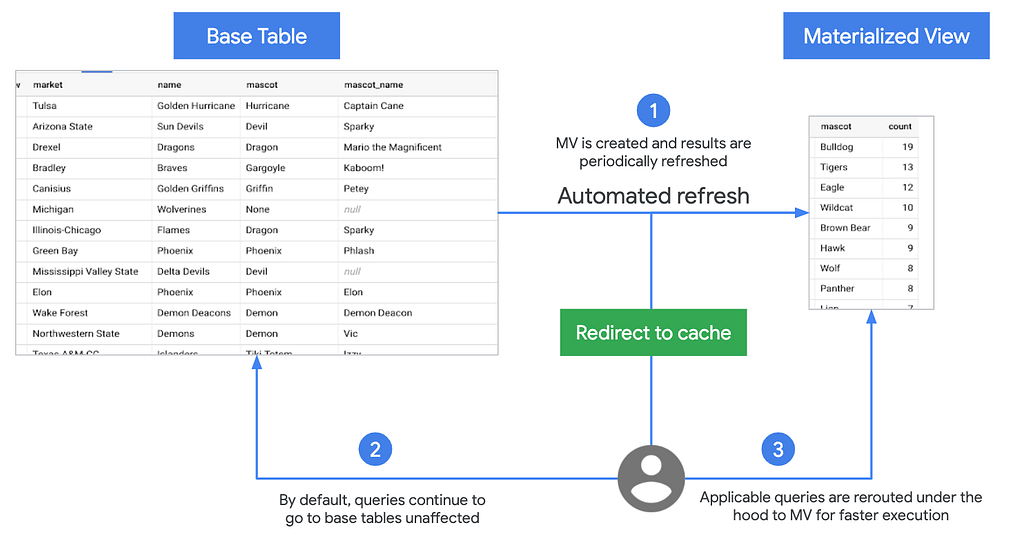
Las siguientes son las características clave de las vistas materializadas:
Mantenimiento cero
- BigQuery aprovecha los resultados precalculados de MV y, siempre que sea posible, lee solo los cambios delta de la tabla base para calcular los resultados actualizados. Sincroniza automáticamente las actualizaciones de datos con los cambios de datos en las tablas base. No se requieren entradas de usuario. También tiene la opción de activar la actualización manual de las vistas para controlar los costos de los trabajos de actualización.
Siempre fresco
- MV siempre es coherente con la tabla fuente. Se pueden consultar directamente o el optimizador de BigQuery puede usarlos para procesar consultas a las tablas base.
Sintonización inteligente
- MV admite la reescritura de consultas. Si, en cambio, una consulta en la tabla de origen se puede resolver consultando la MV, BigQuery reescribirá (redirigirá) la consulta a la MV para obtener un mejor rendimiento o eficiencia.
Usted crea MV usando BigQuery DDL - CREATE MATERIALIZED VIEW declaración .
¿Cuándo usar vistas materializadas?
- MV son adecuados para los casos en los que necesita consultar los datos más recientes mientras reduce la latencia y el costo al reutilizar los resultados calculados previamente. MV actúa como pseudo-índices , acelerando las consultas a la tabla base sin actualizar ningún flujo de trabajo existente.
Limitaciones de las vistas materializadas
- En el momento de escribir este artículo, las uniones no se admiten actualmente en MV. Sin embargo, puede aprovechar MV en una consulta que realiza agregación sobre combinaciones. Esto reduce el costo y la latencia de la consulta.
- MV admite un conjunto limitado de funciones de agregación y SQL restringido. Consulte los patrones de consulta admitidos por vistas materializadas .
Consulte la documentación de BigQuery para trabajar con vistas materializadas y prácticas recomendadas.
¿Qué sigue?
En esta publicación, revisamos el ciclo de vida de una consulta SQL en BigQuery, trabajando con funciones de ventana, creando vistas estándar y materializadas, guardando y compartiendo consultas.
Referencias
- Referencia de funciones de BigQuery
- Funciones analíticas (ventana) en BigQuery
- Vistas estándar en BigQuery [ Docs ]
- Vistas materializadas en BigQuery [ Docs ]
- Guardar y compartir consultas [ Video ] [ Docs ]
- Prácticas recomendadas de BigQuery para el rendimiento de las consultas
Codelab
- Pruebe este laboratorio de código para consultar un gran conjunto de datos públicos basado en archivos de Github.
En la próxima publicación, nos sumergiremos en las uniones, optimizando los patrones de unión y desnormalizando los datos con estructuras de datos anidadas y repetidas.
Manténganse al tanto. ¡Gracias por leer! ¿Tienes alguna pregunta o quieres charlar? Encuéntrame en Twitter o LinkedIn .
Gracias a Yuri Grinshsteyn y Alicia Williams por ayudarnos con la publicación.
Explicación de BigQuery: Querying your Data se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación destacando y respondiendo a esta historia.