
¿Cuántas veces se sorprendió cuando su aplicación favorita le mostró contenido relevante?
Ya sea que esté usando Youtube, Netflix o cualquier otra aplicación, notará que el sistema de recomendación es el factor principal en su éxito, pero tener un sistema de recomendación podría ser un poco pesado para su inicio, agregando algoritmos de aprendizaje automático como filtrado / contenido colaborativo. -basado en el filtrado, después de eso, necesitas entrenar un modelo basado en tu big data, al final terminarás con un modelo estático para predecir la relevancia del contenido para el usuario.
El enfoque anterior es difícil y costoso de aplicar, cualquier entrenamiento de modelo tomará horas, ¡y eso podría hacer que su motor de recomendación sea inútil con el tiempo!, La deriva del modelo es un problema que lo perseguirá todo el tiempo, los datos de los usuarios siguen cambiando en un forma muy rápida.
Solución alternativa
La solución que propondría aquí está relacionada con los agregadores de noticias. ¡Está usando reglas explícitas, a diferencia del ML! puede cambiar las reglas para que coincidan con su dominio.
Los agregadores de noticias crean una lista seleccionada de artículos de diferentes editores / temas y permiten a los usuarios seguir a los editores y leer artículos, los agregadores de noticias inteligentes intentan brindarle al usuario artículos relevantes, según el caso de estudio, notamos algunas reglas para mejorar la experiencia del usuario cuando se trata de servir artículos:
El usuario está interesado en artículos de temas específicos.
El usuario prefiere algunos editores más que otros.
El usuario prefiere los artículos que hablan con algunas palabras clave principales.
El recomendador no debe recomendar artículos que los usuarios ya hayan leído.
Este Recomendador es simple, ya que es un comando que se ejecuta como un trabajo cron para agregar artículos recomendados para los usuarios por horas, el trabajo se realizará en modo fuera de línea para preparar los artículos recomendados para ser enviados / resaltados para los usuarios, este trabajo puede tardar unos minutos en ejecute incluso cuando tenga miles de artículos y cientos de miles de usuarios.
BigQuery
¿Por qué preferí usar BigQuery en primer lugar?
BigQuery es un servicio sin servidor de GCP (Google Cloud Platform), muy eficiente y potente para el trabajo de BigData, se puede integrar con otros servicios de GCP de una forma muy sencilla, sin necesidad de hacer ningún sysops ni hosting, y cuenta con CLI y SDK en muchos lenguajes de programación modernos como PHP, Go, node.js… etc, es fácil de cargar datos, tiene 2 enfoques diferentes para la facturación y muchas otras razones, solo échale un vistazo desde aquí .
Asegúrese de usar BigQuery como almacén, guarde una copia allí para el almacenamiento a largo plazo, probablemente necesite crear canalizaciones ETL para seguir moviendo datos de su DB / ES a BigQuery, GCP proporciona una herramienta para manejar eso por usted Google Data Fusion
¡Plato principal!
Primero, todas las consultas aquí y los datos de ejemplo están disponibles en Github .
No discutiré cómo vas a usar esta consulta, para mí usaría Laravel , tiene una buena manera de construir comandos usando Artisan Console , ¡solo necesitas agregar PHP BigQuery SDK a tu compositor!
Aquí están los datos que necesitamos procesar, tabla de artículos para artículos candidatos, usuario la tabla que tiene usuarios, cada artículo pertenece al tema y al editor.
user_article_feed conserva los artículos que el usuario ha visto en el feed.
user_article_read conserva los artículos que el usuario ha leído antes.
Para explorar la tabla de artículos, ejecutemos:
seleccione * de test_data.article

En la tabla de usuarios, tenemos 1000 usuarios (id, nombre).
Basándonos en los datos históricos del usuario, podemos notar que el usuario X podría estar interesado en algunos temas / editores en función de las vistas / acciones / reacciones / CTR ... etc., a partir de estos datos podemos generar una puntuación de relevancia MÉTRICA del usuario (0 -> 1 ), y aquí vinieron user_publisher y user_topic, ambas son tablas precalculadas y deben mantenerse bien y actualizarse con frecuencia.


En este ejemplo, tenemos 100 artículos diferentes y 1000 usuarios, lo que significa que tenemos 100,000 combinaciones diferentes, cada usuario tiene 100 artículos diferentes que puede leer, pero al final, un solo usuario necesita los X artículos más relevantes, BigQuery puede ofrecer los mejores y experiencia escalable para hacer eso, ¡simplemente usando SQL estándar!
Te mostraré la consulta simple que puede lograr eso:
con artículo como
(
seleccione * de test_data.article
),
usuario como (
seleccione * de test_data.user
),
tema como (
seleccionar * de test_data.topic
),
user_read como (
seleccione * de `test_data.user_article_read`
),
user_feed como (
seleccione * de `test_data.user_article_feed`
),
user_publisher como (
seleccione * de test_data.user_publisher
),
user_topic como (
seleccione * de test_data.user_topic
),
artículos_ mejorados como (
Seleccione *,
ROW_NUMBER () sobre (Partition BY article.topic_id ORDER BY score DESC) como article_rank,
max (score) sobre (Partition BY article.topic_id) como article_max_score,
min (puntuación) sobre (Partition BY article.topic_id) como article_min_score,
1000 * (score / max (score) over (Partition BY article.topic_id)) como advanced_scroll
del artículo
),
user_article como (
seleccione user.id como user_id, article.id como article_id, article.score como original_score, article.publisher_id, article.topic_id, article.enhanced_scroll
de la unión cruzada de usuario advanced_articles como artículo
),
user_article_with_dimension_relevance como (
seleccione artículo_usuario. *,
user_publisher.relevance como user_publisher_relevance,
user_topic.relevance como user_topic_relevance
de user_article
unirse a la izquierda user_publisher en user_publisher.user_id = user_article.user_id y user_article.publisher_id = user_publisher.publisher_id
unirse a la izquierda user_topic en user_topic.user_id = user_article.user_id y user_topic.topic_id = user_article.topic_id
),
user_article_check_read_and_feed como (
seleccione distinto user_article_with_dimension_relevance. *,
SI (user_read.article_id es nulo, 0, 1) como se lee,
IF (user_feed.article_id es nulo, 0, 1) como fuente
de user_article_with_dimension_relevance
unión izquierda user_feed en user_feed.user_id = user_article_with_dimension_relevance.user_id y user_feed.article_id = user_article_with_dimension_relevance.article_id
unión izquierda user_read en user_read.user_id = user_article_with_dimension_relevance.user_id y user_read.article_id = user_article_with_dimension_relevance.article_id
),
user_article_filtered como (
seleccione * de user_article_check_read_and_feed donde read = 1 o feed = 1 o user_publisher_relevance = 0 o user_topic_relevance = 0
),
user_article_with_relevance_score como (
seleccione u.user_id, u.article_id, u.original_score, u.publisher_id, u.topic_id, ((user_publisher_relevance + user_topic_relevance) / 2) como relevancia_score, u.enhanced_scroll
de user_article_filtered como u
),
user_article_with_calculated_score como (
seleccione *, (advanced_scroll * relevancia_score) user_article_relevance_score,
ROW_NUMBER () sobre (Partition BY user_id ORDER BY (advanced_scroll * relevancia_score) DESC) como user_article_rank,
de user_article_with_relevance_score
),
user_with_top_articles como (
seleccione user_id,
to_json_string (ARRAY_AGG (
ESTRUCTURA(article_id, original_score, publisher_id, topic_id, relevancia_score, advanced_scroll, user_article_relevance_score, user_article_rank)
) ) datos
de user_article_with_calculated_score
donde user_article_rank <= 5
agrupar por user_id
)
seleccionar * de user_with_top_articles
Por lo tanto, esta consulta se considera una canalización de pasos o una consulta recursiva, la ejecución es de abajo hacia arriba, pero la discutiremos de arriba hacia abajo.
Saltaré las primeras subconsultas porque es demasiado simple, mejorar_artículos está destinado a hacer un terreno común para la puntuación de los artículos, porque el valor de la puntuación del artículo puede variar de diferentes temas, por lo que hacemos la puntuación del artículo como un valor de 0 -> 1000.
user_article_with_dimension_relevance Tendrá todas las combinaciones de usuario-artículo con la puntuación del artículo, la puntuación del artículo-tema del usuario y la puntuación del artículo-editor del usuario.
user_article_check_read_and_feed en este paso, filtraremos algunas filas, si el usuario lee el artículo o se metió dentro de su feed, no es necesario volver a recomendarlo, por lo que bajará el número de artículos candidatos para el usuario.
user_article_with_calculated_score aquí calculamos la puntuación de los artículos del usuario en función de la puntuación del artículo y la puntuación del usuario-artículo-tema / usuario-artículo-editor
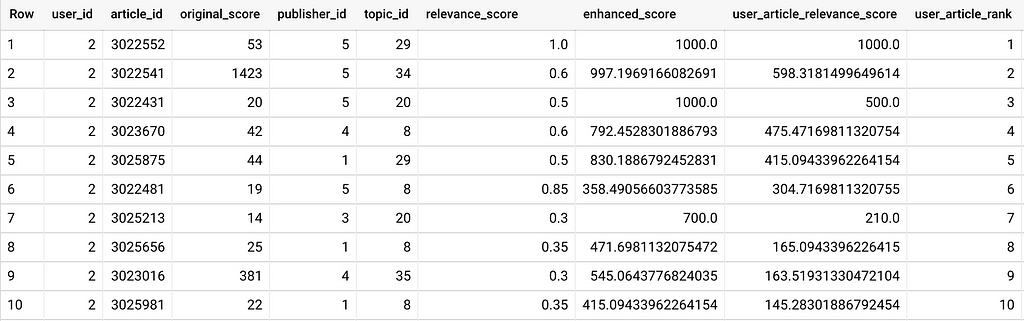
El primer artículo recomendado para el usuario n. ° 2 tiene una puntuación baja en comparación con otro artículo, pero su 'tema y editor es el preferido por el usuario, y ese artículo tiene la mejor puntuación (1000) en su' tema, y el usuario no ha ' Si aún no leíste ese artículo, eso significa que hay muchas posibilidades de que capte la atención del usuario.
Además, notamos que el segundo artículo recomendado para el usuario n. ° 2 es un artículo que tiene una puntuación de artículo más baja en comparación con el tercero, ambos tienen el mismo editor, pero de un tema diferente, y ese usuario está más interesado en el tema n. ° 34 en comparación con tema n. ° 20, por lo que la nueva puntuación será (puntuación de relevancia + desplazamiento mejorado del artículo) / 2 como puntuación final que se utilizará en la clasificación de los artículos.
user_with_top_articles este paso es solo para cambiar la forma de salida, para facilitar que su comando obtenga resultados, por lo que en lugar de obtener X filas para cada usuario, obtiene 1 fila por usuario y los artículos se agrupan en una matriz JSON.

Conclusión
BigQuery es una herramienta poderosa que puede procesar terabytes de datos en segundos / minutos, puede usar ese poder en trabajos en segundo plano de muchas maneras diferentes, aquí mostré un enfoque simple que uso para procesar ~ 100GB de datos en 2 minutos, solo usando SQL.
El motor de recomendación es una parte muy crucial en su aplicación, esta es muy simple para los equipos que no tienen un científico de ML, también es un ejemplo para mostrarle cómo se puede usar BigQuery.
No dude en compartir sus pensamientos en los comentarios a continuación. Si tiene alguna pregunta o comentario, ¡no dude en preguntarlo!
Recomendar contenido personalizado para los usuarios de su aplicación que usan BigQuery se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación destacando y respondiendo a esta historia.