A veces, los datos duplicados pueden causar agregados o resultados incorrectos. Probablemente necesite eliminar esas filas duplicadas antes de realizar cualquier agregación, combinación o cálculo. Hay varias formas de lidiar con los datos duplicados y puede encontrar uno de estos métodos para lidiar con las claves / columnas / filas duplicadas en esta publicación.
Caso 1; Obtenga solo una fila única por columna clave
Datos de ejemplo:
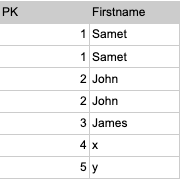
Aquí puede ver que hay algunos duplicados de filas completas, puede usar la siguiente consulta para deduplicar esta tabla:
crear tabla dataset.table_name_dedup como (
seleccione * excepto (fila_num) de (
SELECCIONE
*,
ROW_NUMBER () SOBRE (
PARTICIÓN POR
DB_PK
PEDIR POR
DB_PK
) fila_num
DESDE
dataset.table_name) t
DONDE row_num = 1
)
Como habrás reconocido, estamos creando una nueva tabla en lugar de sobrescribir la tabla existente. Si desea sobrescribir la tabla existente, puede usar el mismo nombre con crear o reemplazar:
crear o reemplazar tabla dataset.table_name como (
seleccione * excepto (fila_num) de (
SELECCIONE
*,
ROW_NUMBER () SOBRE (
PARTICIÓN POR
DB_PK
PEDIR POR
DB_PK
) fila_num
DESDE
dataset.table_name) t
DONDE row_num = 1
)
Caso-2; Deduplicar con un criterio como mantener lo más nuevo
Si tiene algunos criterios para la eliminación, como una columna de fecha, puede cambiar la clave de pedido como:

crear o reemplazar tabla dataset.table_name como (
seleccione * excepto (fila_num) de (
SELECCIONE
*,
ROW_NUMBER () SOBRE (
PARTICIÓN POR
DB_PK
PEDIR POR
creation_date desc
) fila_num
DESDE
dataset.table_name) t
DONDE row_num = 1
)
Caso 3; Deduplicar basado en múltiples columnas
Si tiene varias claves de columna o elimina duplicados basados en algunas columnas, puede usar esas columnas dentro de la cláusula PARTITION BY:
Ejemplo: deduplicar según el nombre y el apellido
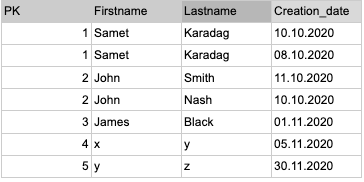
crear o reemplazar tabla dataset.table_name como (
seleccione * excepto (fila_num) de (
SELECCIONE
*,
ROW_NUMBER () SOBRE (
PARTICIÓN POR
Nombre Apellido
PEDIR POR
creation_date desc
) fila_num
DESDE
dataset.table_name) t
DONDE row_num = 1
)
Hágame saber su método preferido comentando en esta publicación.
Cómo desduplicar filas en una tabla de BigQuery se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.