Agregar una capa de caché a las bases de datos de Google Cloud (Bigtable + Memcached)
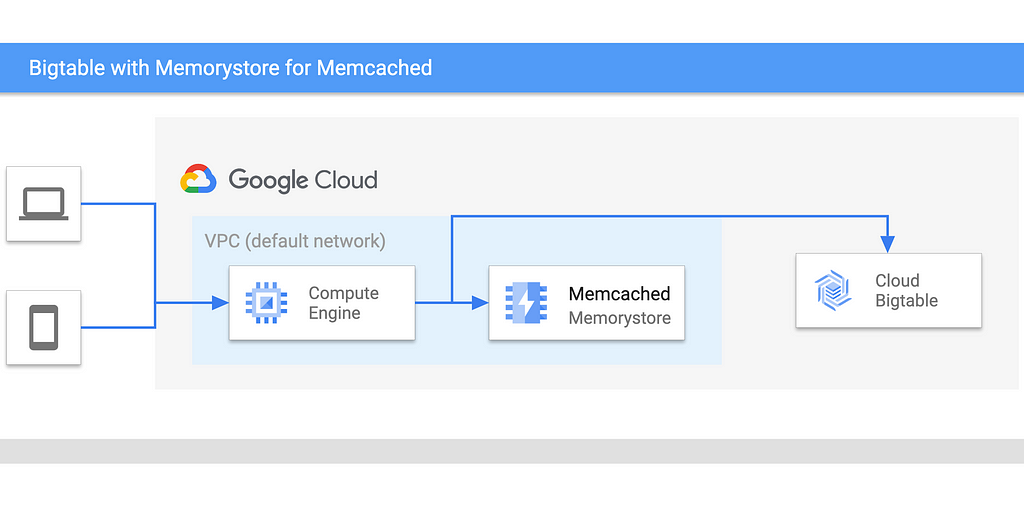
TLDR: mejore el rendimiento de su aplicación utilizando Memcached para datos consultados con frecuencia como este:
Las bases de datos están diseñadas para esquemas, consultas y rendimiento específicos, pero si tiene datos que se consultan con más frecuencia durante un período de tiempo, es posible que desee reducir la carga en su base de datos mediante la introducción de una capa de caché.
En esta publicación, veremos Google Cloud Bigtable escalable horizontalmente, que es ideal para lecturas y escrituras de alto rendimiento. El rendimiento se puede optimizar asegurándose de que las filas se consulten de manera algo uniforme en la base de datos. Si introducimos una caché para las filas consultadas con más frecuencia, aceleramos nuestra aplicación de dos maneras: estamos reduciendo la carga en las filas con puntos de acceso y acelerando las respuestas al colocar la caché y la computación.
Memcached es un almacén de valores-clave en memoria para pequeños fragmentos de datos arbitrarios, y voy a utilizar el Memorystore escalable y totalmente administrado para Memcached (Beta), ya que está bien integrado con el ecosistema de Google Cloud.
Preparar
- Cree un nuevo proyecto de Google Cloud o use un proyecto existente y una base de datos de su elección. Los ejemplos aquí mostrarán Cloud Bigtable , pero Spanner o Firestore también serían buenas opciones.
- Proporcionaré comandos de gcloud para la mayoría de los pasos, pero puede hacer la mayor parte en Google Cloud Console si lo prefiere.
- Crea una instancia de Cloud Bigtable y una tabla con una fila con estos comandos:
cbt createinstance bt-cache "Bigtable con caché" bt-cache-c1 us-central1-b 1 SSD
cbt -instance = bt-cache createtable mobile-time-series "familias = stats_summary"
cbt -instance = bt-cache set mobile-time-series phone # 4c410523 # 20190501 stats_summary: os_build = PQ2A.190405.003
stats_summary: os_name = android
# Verifique que esto funcionó leyendo los datos.
cbt -instance = bt-cache read mobile-time-series
El código
La lógica genérica de una caché se puede definir en los siguientes pasos:
Elija una clave de fila para consultar
Si la clave de fila está en la caché
Devuelve el valor
De otra manera
Busque la fila en Cloud Bigtable
Agregue el valor a la caché con vencimiento
Devuelve el valor
Para Cloud Bigtable, su código podría verse así ( código completo en GitHub ):
Elegí hacer que la clave de caché sea row_key: column_family: column_qualifier para acceder fácilmente a los valores de columna. A continuación, se muestran algunos pares de clave / valor de caché potenciales que puede utilizar:
- rowkey: fila codificada
- start_row_key-end_row_key: matriz de filas codificadas
- Consultas SQL: resultados
- prefijo de fila: matriz de filas codificadas
Al crear su caché, determine la configuración según su caso de uso. Tenga en cuenta que las claves de fila de Bigtable tienen un límite de tamaño de 4 KB, mientras que las claves de Memcached tienen un límite de tamaño de 250 bytes, por lo que su clave de fila podría ser demasiado grande.
Crear instancia de Memcached
Crearé una instancia de Memorystore para Memcached, pero puedes instalar y ejecutar una instancia local de Memcached para probar esto o para probar. Estos pasos se pueden realizar con Memorystore Cloud Console si lo prefiere.
- Habilita la API de Memorystore para Memcached.
Los servicios de gcloud habilitan memcache.googleapis.com
2. Cree una instancia de Memcached con el tamaño más pequeño en la red predeterminada. Utilice una región que sea apropiada para su aplicación.
Las instancias de memcache beta de gcloud crean bigtable-cache --node-count = 1 --node-cpu = 1 --node-memory = 1GB --region = us-central1
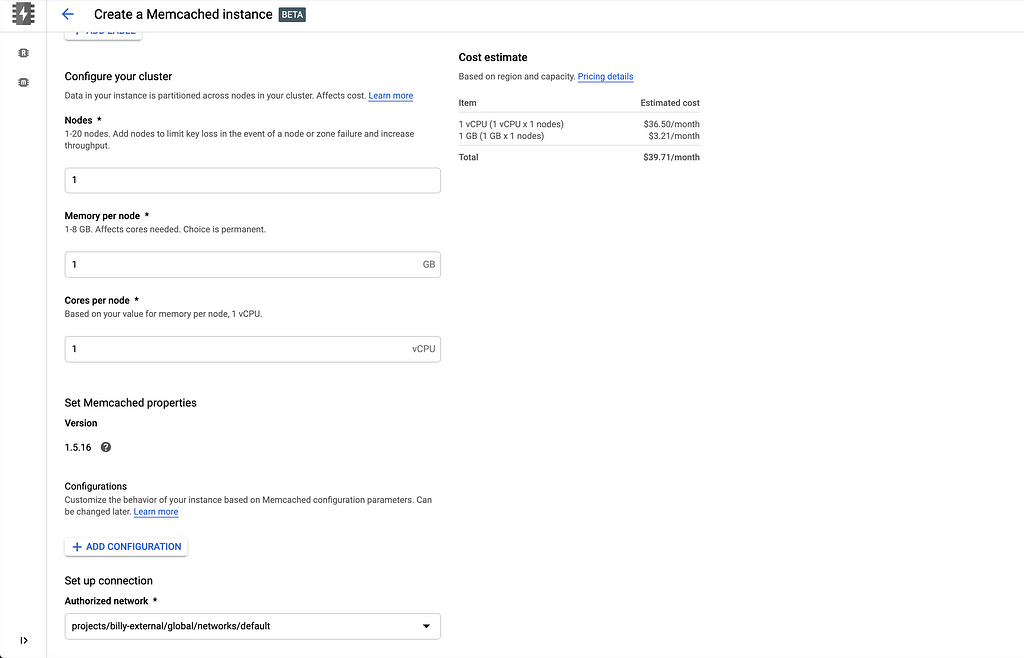
3. Obtenga los detalles de la instancia de Memcached y obtenga la dirección IP de discoveryEndpoint (es posible que deba esperar unos minutos para que la instancia termine de crearse).
Las instancias de memcache beta de gcloud describen bigtable-cache --region = us-central1
Configurar la máquina dentro de la red
Necesitamos crear un lugar para ejecutar código en la misma red que nuestra instancia de Memcached. Puede usar una opción sin servidor como Cloud Functions, pero una VM Compute requiere menos configuración.
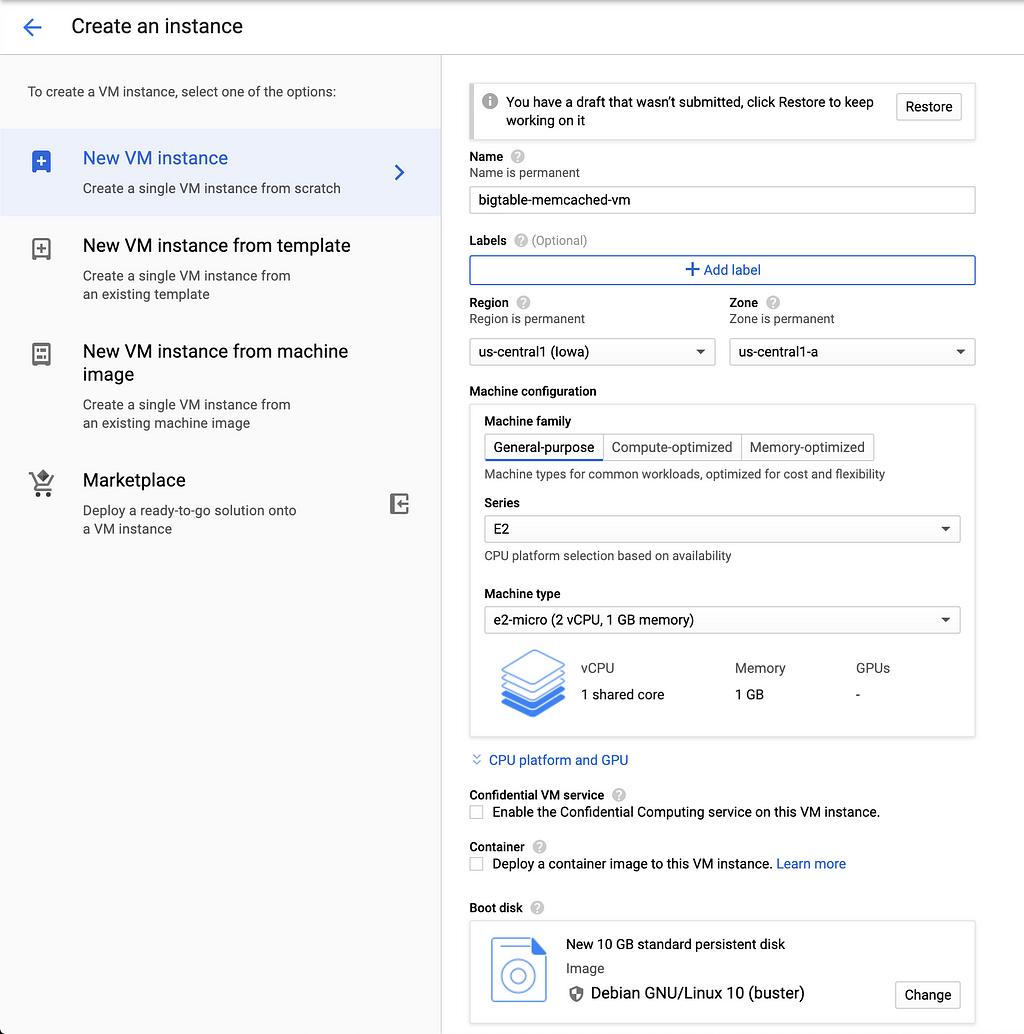
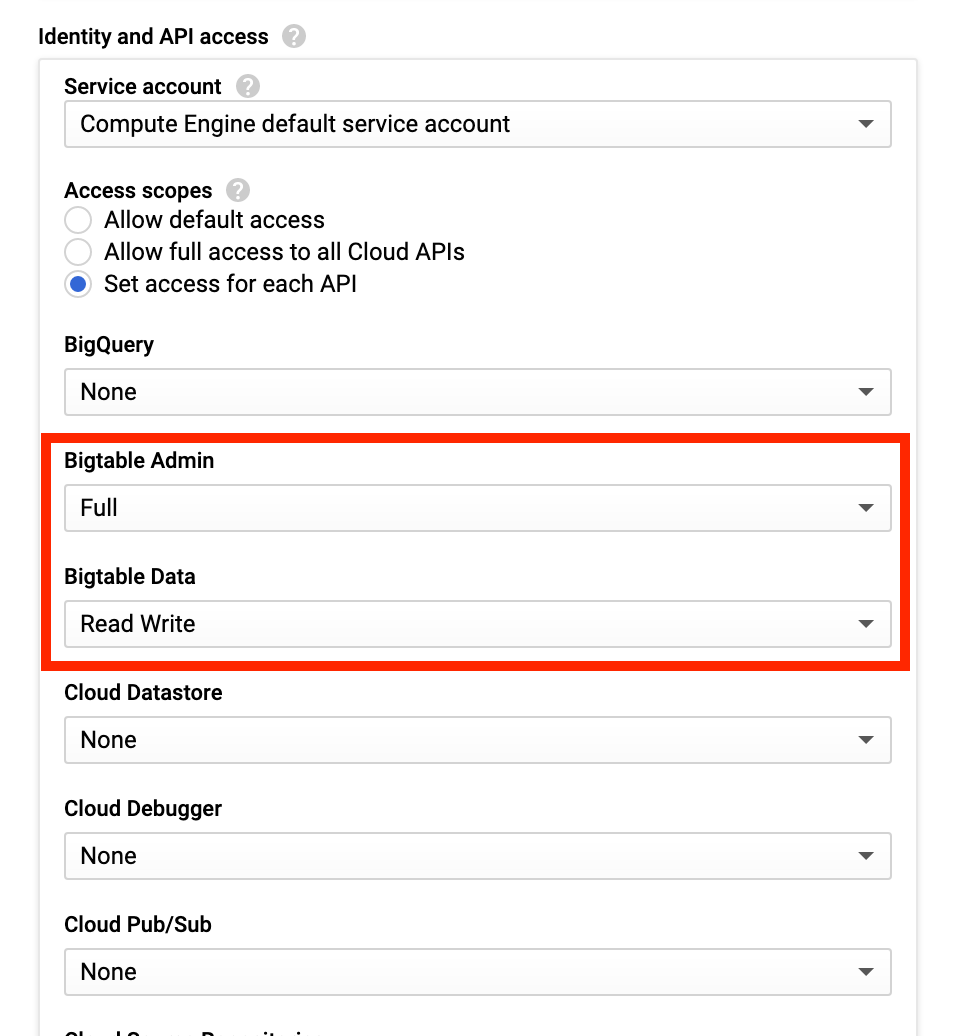
- Crea una instancia informática en la red predeterminada con alcances de API habilitados para los datos de Cloud Bigtable. Tenga en cuenta que la zona debe estar en la misma región que su instancia de Memcached.
Las instancias de computación beta de gcloud crean bigtable-memcached-vm --zone = us-central1-a --machine-type = e2-micro --image = debian-10-buster-v20200910 --image-project = debian-cloud - boot-disk-size = 10GB --boot-disk-type = pd-standard --boot-disk-device-name = bigtable-memcached-vm --scopes = https: //www.googleapis.com/auth/bigtable .data, https: //www.googleapis.com/auth/servicecontrol,https: //www.googleapis.com/auth/service.management.readonly,https: //www.googleapis.com/auth/logging.write , https: //www.googleapis.com/auth/monitoring.write,https: //www.googleapis.com/auth/trace.append,https: //www.googleapis.com/auth/devstorage.read_only
2. SSH en su nueva máquina virtual.
gcloud beta compute ssh --zone "us-central1-a" bigtable-memcached-vm
Opcionalmente conéctese a Memcached a través de Telnet
La documentación de Memorystore para Memcached contiene más información sobre este proceso, pero puede ejecutar los siguientes comandos para configurar y obtener un valor en la caché.
sudo apt-get install telnet
telnet $ DISCOVERY_ENDPOINT_ID 11211
establecer saludo 1 0 11
Hola Mundo
recibir saludo
Ejecutar el código
Ahora estamos listos para poner nuestro código en la máquina.
- Puede clonar el repositorio directamente en la máquina virtual y ejecutarlo desde allí. Si desea personalizar el código, consulte mi artículo sobre sincronización de código en Compute Engine o use el comando gcloud scp para copiar su código desde su máquina local a su VM.
sudo apt-get install git
clon de git https://github.com/GoogleCloudPlatform/java-docs-samples.git
cd java-docs-samples / bigtable / memorystore
2. Instalar maven
sudo apt-get install maven
3. Establezca las variables de entorno para su configuración.
PROJECT_ID = id-de-tu-proyecto
MEMCACHED_DISCOVERY_ENDPOINT = "0.0.0.0" # Obtenga esto del comando de descripción de memcache anterior. Excluir el sufijo ': 11211'
4. Ejecute el programa una vez para obtener el valor de la base de datos, luego ejecútelo nuevamente y verá que el valor se obtiene de la caché.
mvn compilar exec: java -Dexec.mainClass = Memcached \
-DbigtableProjectId = $ ID_PROYECTO \
-DbigtableInstanceId = bt-cache \
-DbigtableTableId = serie-temporal-móvil \
-DmemcachedDiscoveryEndpoint = $ MEMCACHED_DISCOVERY_ENDPOINT
Próximos pasos y limpieza
Ahora debe comprender los conceptos básicos para colocar una capa de caché frente a su base de datos y puede integrarla en su aplicación existente. Si siguió esta publicación de blog, borre su VM, instancia de Cloud Bigtable y instancia de Memcached con estos comandos para evitar que se le facturen los recursos:
cbt deleteinstance bt-cache
Las instancias de memcache beta de gcloud eliminan bigtable-cache --region = us-central1
Las instancias de computación de gcloud eliminan bigtable-memcached-vm --zone = us-central1-a
Agregar una capa de caché a las bases de datos de Google Cloud (Memcached + Bigtable) se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.