En la publicación anterior de la serie BigQuery Explained, revisamos la arquitectura de alto nivel de BigQuery y mostramos cómo comenzar con BigQuery. En esta publicación, analizaremos la organización de almacenamiento de BigQuery, el formato de almacenamiento y presentaremos una de las mejores prácticas de BigQuery para particionar y agrupar sus datos para un rendimiento óptimo. ¡Vamos a sumergirnos en él!
Modelo de recursos de BigQuery
BigQuery organiza las tablas de datos en unidades llamadas conjuntos de datos. Estos conjuntos de datos tienen como alcance su proyecto de GCP. Estos múltiples alcances (proyecto, conjunto de datos y tabla) lo ayudan a estructurar su información de manera lógica. Puede utilizar varios conjuntos de datos para separar tablas pertenecientes a diferentes dominios analíticos, y puede utilizar el alcance a nivel de proyecto para aislar conjuntos de datos entre sí de acuerdo con sus necesidades comerciales.
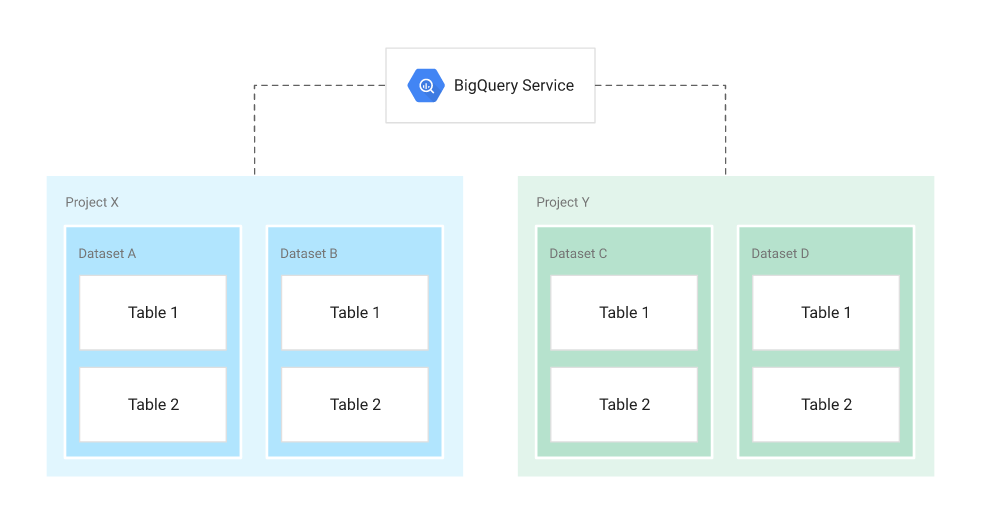
Proyectos
- Espacio de nombres raíz para objetos
- Contiene múltiples conjuntos de datos, trabajos, listas de control de acceso y roles de IAM
- Controle la facturación, los usuarios y los privilegios de los usuarios
Conjuntos de datos
- Colecciones de tablas / vistas "relacionadas" junto con etiquetas y descripción
- Permitir el control de acceso al almacenamiento a nivel de conjunto de datos
- Definir la ubicación de los datos, es decir, multirregional (EE. UU., UE) o regional (asia-noreste1)
Mesas
- Colecciones de columnas y filas almacenadas en almacenamiento administrado
- Definido por un esquema con columnas de valores fuertemente tipadas
- Permitir el control de acceso a nivel de tabla y columna
Puntos de vista
- Tablas virtuales definidas por una consulta SQL
- Permitir el control de acceso a nivel de vista
Trabajos
- Acciones que BigQuery ejecuta en su nombre: cargar datos, exportar datos, copiar datos o consultar datos
- Los trabajos se ejecutan de forma asincrónica
Cuando hace referencia a una tabla desde la línea de comandos, en consultas SQL o en el código, se hace referencia a ella utilizando la siguiente construcción: project.dataset.table.
Administración de almacenamiento
Ahora revisemos cómo BigQuery administra el almacenamiento que contiene sus datos. Las bases de datos relacionales tradicionales, como MySQL, almacenan datos fila por fila ( almacenamiento orientado a registros ). Esto los hace buenos para las actualizaciones transaccionales y los casos de uso de OLTP (procesamiento de transacciones en línea). BigQuery, por otro lado, usa almacenamiento en columnas, donde cada columna se almacena en un bloque de archivos separado. Esto convierte a BigQuery en una solución ideal para casos de uso de OLAP (procesamiento analítico en línea). Puede transmitir (agregar) datos fácilmente a las tablas de BigQuery y actualizar o eliminar los valores existentes. BigQuery admite mutaciones (INSERT, UPDATE, MERGE, DELETE) sin límites.
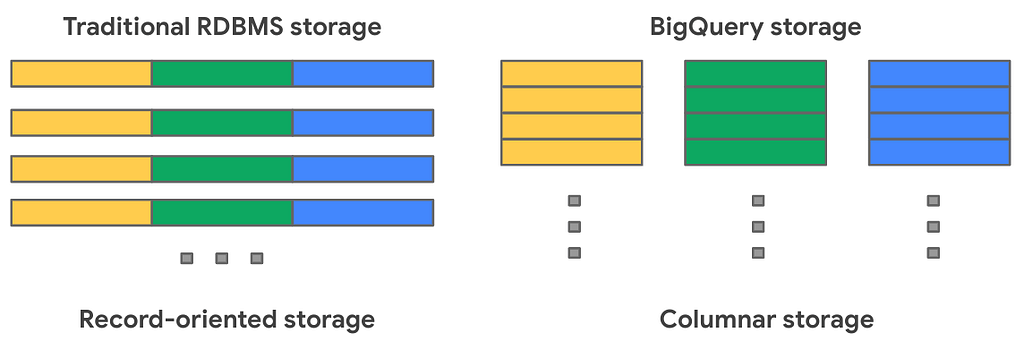
BigQuery usa variaciones y avances en el almacenamiento en columnas. Internamente, BigQuery almacena datos en un formato de columnas patentado llamado Capacitor , que tiene una serie de beneficios para las cargas de trabajo del almacén de datos. BigQuery usa un formato propietario porque el motor de almacenamiento puede evolucionar en conjunto con el motor de consultas, que aprovecha el conocimiento profundo del diseño de datos para optimizar la ejecución de consultas. Cada columna de la tabla se almacena en un bloque de archivo separado y todas las columnas se almacenan en un solo archivo de condensador, que se comprime y encripta en el disco. BigQuery usa patrones de acceso a consultas para determinar la cantidad óptima de fragmentos físicos y cómo se codifican los datos.
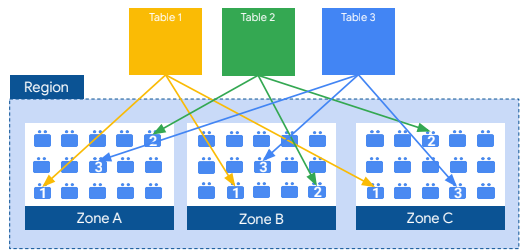
La capa de persistencia real la proporciona el sistema de archivos distribuidos de Google, Colossus , donde los datos se comprimen, cifran, replican y distribuyen automáticamente. Colossus garantiza la durabilidad mediante la codificación de borrado para almacenar fragmentos redundantes de datos en varios discos físicos. Todo esto se logra sin afectar la potencia informática disponible para sus consultas. Separar el almacenamiento de la computación le permite escalar a petabytes en el almacenamiento sin problemas, sin requerir costosos recursos de computación adicionales. Hay una serie de otros beneficios de desacoplar el procesamiento y el almacenamiento.
Aproveche el almacenamiento a largo plazo
Puede cargar datos en BigQuery sin costo (para cargas por lotes) porque los costos de almacenamiento de BigQuery se basan en la cantidad de datos almacenados (los primeros 10 GB son gratuitos cada mes) y si el almacenamiento se considera activo o de largo plazo.
- Si tiene una tabla o partición modificada en los últimos 90 días, se considera almacenamiento activo e incurre en un cargo mensual por los datos almacenados a las tasas de almacenamiento de BigQuery.
- Si tiene una tabla o partición que no se modifica durante 90 días consecutivos, se considera almacenamiento a largo plazo y el precio del almacenamiento para esa tabla cae automáticamente en un 50% al mismo costo que Cloud Storage Nearline . El descuento se aplica por tabla, por partición. Si modifica los datos de la tabla, el contador de 90 días se reinicia.

Una práctica recomendada a la hora de optimizar los costos es mantener sus datos en BigQuery. En lugar de exportar sus datos más antiguos a otra opción de almacenamiento (como Cloud Storage), aproveche los precios de almacenamiento a largo plazo de BigQuery. Esto significa no tener que eliminar datos antiguos o diseñar un proceso de archivo de datos. Dado que los datos permanecen en BigQuery, también puede consultar datos más antiguos con la misma interfaz, a los mismos niveles de costo y con las mismas características de rendimiento.
Particionamiento y agrupación
Mantener los datos en BigQuery es una práctica recomendada si busca optimizar tanto el costo como el rendimiento. Otra práctica recomendada es utilizar las funciones de agrupación y particionamiento de tablas de BigQuery para estructurar tus datos de modo que coincidan con los patrones de acceso a datos comunes.
Fraccionamiento
Una tabla particionada es una tabla especial que se divide en segmentos, llamados particiones, que facilitan la administración y consulta de sus datos. Por lo general, puede dividir tablas grandes en muchas particiones más pequeñas utilizando el tiempo de ingestión de datos o la columna TIMESTAMP / DATE o una columna INTEGER. La arquitectura de computación y almacenamiento desacoplada de BigQuery aprovecha la partición basada en columnas simplemente para minimizar la cantidad de datos que los trabajadores de las ranuras leen del disco. Una vez que los trabajadores de las tragamonedas leen sus datos del disco, BigQuery puede determinar automáticamente una fragmentación de datos más óptima y volver a dividirlos rápidamente mediante el servicio de reproducción aleatoria en memoria de BigQuery.
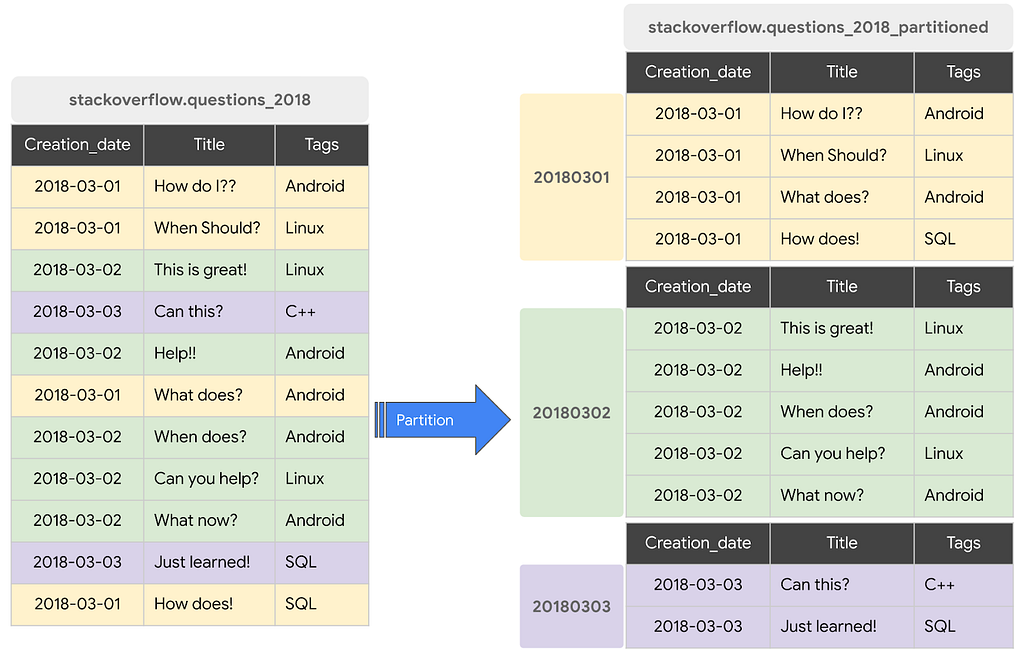
Los datos escritos en una tabla con particiones de tiempo basada en columnas se entregan automáticamente a la partición adecuada según el valor de los datos. De manera similar, las consultas que expresan filtros en la columna de partición pueden reducir los datos generales escaneados, lo que puede producir un rendimiento mejorado y un costo de consulta reducido para las consultas bajo demanda.
BigQuery admite las siguientes formas de crear tablas particionadas
Tablas particionadas por tiempo de ingestión
- Particionado según la hora de ingestión de datos o la hora de llegada.
- BigQuery carga automáticamente datos en particiones diarias basadas en fechas que reflejan la ingestión o la hora de llegada de los datos.
- BigQuery agrega dos pseudocolumnas a las tablas particionadas por tiempo de ingestión: una pseudocolumna _PARTITIONTIME que contiene una marca de tiempo basada en la fecha para los datos y una pseudocolumna _PARTITIONDATE que contiene una representación de fecha.
Tablas particionadas por columna DATE / TIMESTAMP
- Particionado según una columna TIMESTAMP o DATE.
- BigQuery enruta los datos a la partición adecuada según el valor de fecha (expresado en UTC) en la columna de partición.
- BigQuery crea dos particiones especiales: la partición __NULL__ para capturar valores NULL de filas en la columna de partición y la partición __UNPARTITIONED__ para datos fuera del rango de fechas permitido.
- Puede crear particiones con granularidad a partir de particiones por horas.
Tablas particionadas de la gama INTEGER
- Particionado basado en una columna entera con valores de inicio, final e intervalo.
- BigQuery crea dos particiones especiales: la partición __NULL__ para capturar los valores NULL de las filas en la columna de partición y la partición __UNPARTITIONED__ para los datos fuera del rango permitido de números enteros.
Veamos la partición en acción. Para ver la diferencia de rendimiento entre una tabla particionada y una no particionada, crearemos tablas particionadas y no particionadas con el mismo conjunto de datos y verificaremos el desempeño de la consulta.
Antes de particionar
Al ejecutar la siguiente consulta SQL, crearemos una tabla no particionada con datos cargados desde un conjunto de datos públicos basados en publicaciones de StackOverflow creando una nueva tabla a partir de una tabla existente . Esta tabla contendrá las publicaciones de StackOverflow creadas en 2018.
CREAR O REEMPLAZAR TABLA `stackoverflow.questions_2018` COMO
SELECCIONE *
DE `bigquery-public-data.stackoverflow.posts_questions`
DONDE fecha_creación ENTRE '2018-01-01' Y '2018-07-01'
Consultemos la tabla no particionada para obtener todas las preguntas de StackOverflow etiquetadas con 'android' en el mes de enero de 2018.
SELECCIONE
carné de identidad,
título,
cuerpo,
accept_answer_id,
fecha de creación,
answer_count,
Recuento de comentarios,
cuenta_favorita,
conteo de visitas
DE
`stackoverflow.questions_2018`
DÓNDE
creation_date ENTRE '2018-01-01' Y '2018-02-01'
Y etiquetas = 'android';
Antes de que se ejecute la consulta, el almacenamiento en caché está deshabilitado para ser justo al comparar el rendimiento con tablas particionadas y agrupadas.
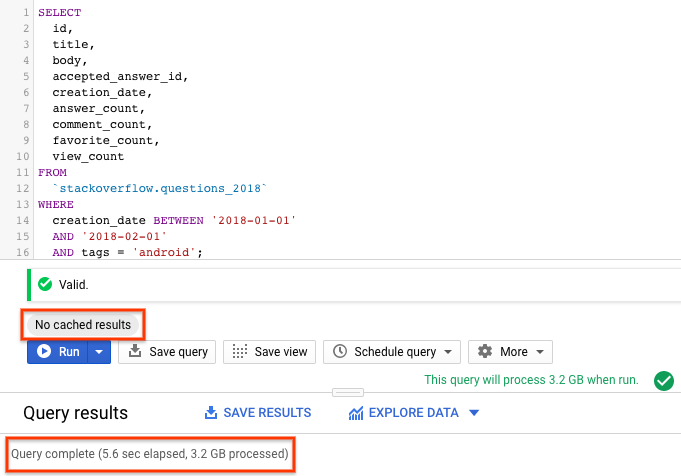
A partir de los resultados de la consulta, puede ver que la consulta en una tabla no particionada tardó 5,6 segundos en escanear los 3,2 GB completos de datos con las publicaciones de StackOverflow creadas en 2018.
Partición de la mesa
Ahora veamos si las tablas particionadas pueden funcionar mejor. Puede crear tablas particionadas de varias formas . Crearemos una tabla particionada DATE / TIMESTAMP usando declaraciones DDL de BigQuery . Elegimos la columna de partición como creation_date en función del patrón de acceso a la consulta.
CREAR O REEMPLAZAR TABLA `stackoverflow.questions_2018_partitioned`
PARTICIÓN POR
FECHA (fecha_creación) AS
SELECCIONE
*
DE
`bigquery-public-data.stackoverflow.posts_questions`
DÓNDE
creation_date ENTRE '2018-01-01' Y '2018-07-01';
Ahora ejecutemos la consulta anterior en la tabla particionada, con el caché deshabilitado , para buscar todas las preguntas de StackOverflow etiquetadas con 'android' en el mes de enero de 2018.
SELECCIONE
carné de identidad,
título,
cuerpo,
accept_answer_id,
fecha de creación,
answer_count,
Recuento de comentarios,
cuenta_favorita,
conteo de visitas
DE
`stackoverflow.questions_2018_partitioned`
DÓNDE
creation_date ENTRE '2018-01-01' Y '2018-02-01'
Y etiquetas = 'android';
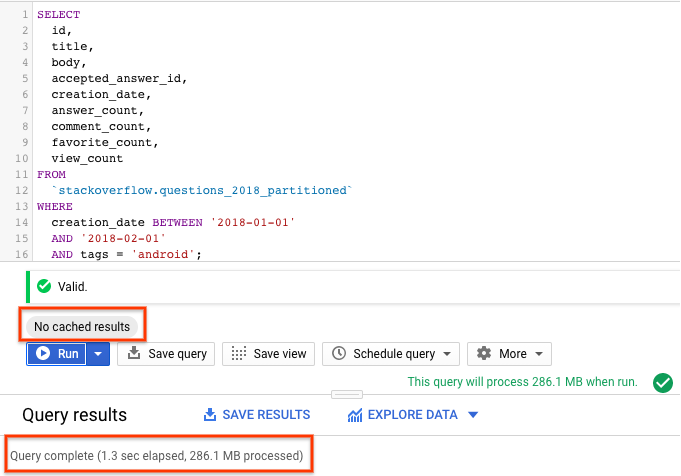
Con la consulta de tabla particionada escaneada solo las particiones requeridas en <2s procesando ~ 290 MB de datos en comparación con la consulta que se ejecuta con tabla no particionada procesando 3.2GB.
La administración de particiones es clave para maximizar por completo el rendimiento y el costo de BigQuery cuando se realizan consultas en un rango específico; da como resultado el escaneo de menos datos por consulta y la poda se determina antes de la hora de inicio de la consulta. Si bien la partición reduce los costos y mejora el rendimiento, también evita la explosión de costos debido a que el usuario consulta accidentalmente tablas realmente grandes en su totalidad.
Sugerencia: Puede controlar y optimizar los costos de almacenamiento configurando la caducidad de la tabla para eliminar tablas y particiones innecesarias.
Obtenga más información sobre las tablas particionadas aquí .
Clustering
Cuando una tabla se agrupa en BigQuery, los datos de la tabla se organizan automáticamente según el contenido de una o más columnas en el esquema de la tabla. Las columnas que especifique se utilizan para colocar datos relacionados. Por lo general, se prefieren las columnas de cardinalidad alta y no temporales para la agrupación.
Cuando los datos se escriben en una tabla agrupada, BigQuery ordena los datos con los valores de las columnas de agrupación. Estos valores se utilizan para organizar los datos en varios bloques en el almacenamiento de BigQuery. El orden de las columnas agrupadas determina el orden de clasificación de los datos. Cuando se agregan datos nuevos a una tabla o una partición específica, BigQuery realiza un reagrupamiento automático en segundo plano para restaurar la propiedad de clasificación de la tabla o partición. La reagrupación automática es completamente gratuita y autónoma para los usuarios.
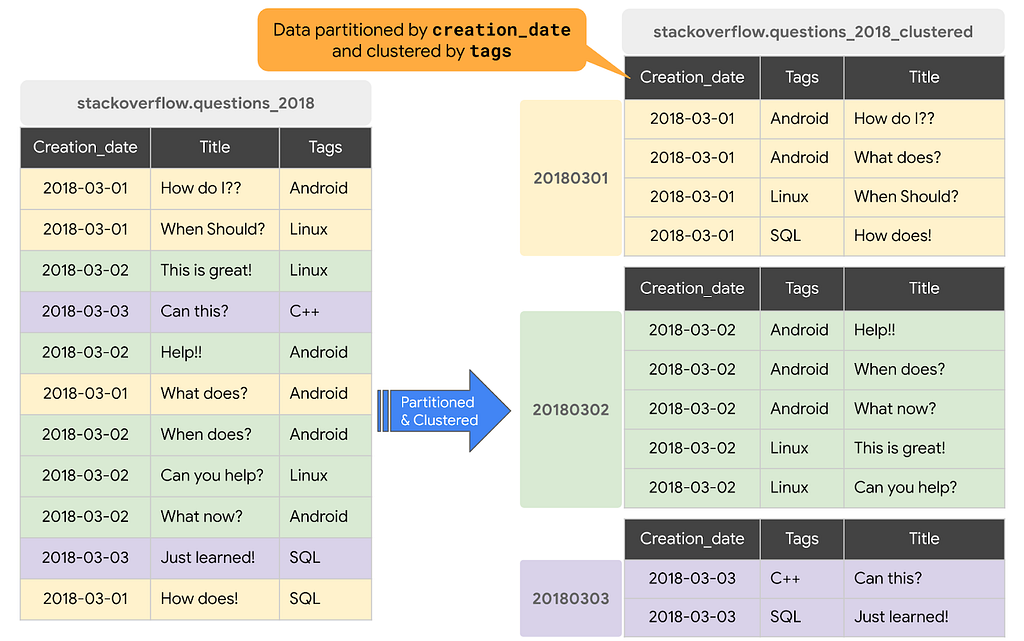
La agrupación en clústeres puede mejorar el rendimiento de ciertos tipos de consultas, como las que utilizan cláusulas de filtro y consultas que agregan datos.
- Cuando una consulta que contiene una cláusula de filtro filtra datos en función de las columnas de agrupación en clúster, BigQuery usa los bloques ordenados para eliminar escaneos de datos innecesarios.
- Cuando una consulta agrega datos basados en los valores en las columnas de agrupamiento, el rendimiento mejora porque los bloques ordenados colocan filas con valores similares.
BigQuery admite la agrupación en clústeres en tablas particionadas y no particionadas. Cuando usa agrupación en clústeres y particiones juntas, sus datos pueden particionarse por una columna DATE o TIMESTAMP y luego agruparse en un conjunto diferente de columnas (hasta cuatro columnas).
Volviendo a la consulta anterior, averigüemos cómo funciona la consulta con tabla agrupada.
Agrupar la mesa
Puede crear tablas agrupadas de varias formas . Crearemos una nueva tabla DATE / TIMESTAMP particionada y agrupada mediante declaraciones DDL de BigQuery . Elegimos la columna de partición como creation_date y la clave de clúster como etiqueta según el patrón de acceso a la consulta.
CREAR O REEMPLAZAR TABLA `stackoverflow.questions_2018_clustered`
PARTICIÓN POR
FECHA (fecha_creación)
AGRUPAR POR
etiquetas AS
SELECCIONE
*
DE
`bigquery-public-data.stackoverflow.posts_questions`
DÓNDE
creation_date ENTRE '2018-01-01' Y '2018-07-01';
Ahora ejecutemos la consulta en la tabla particionada y agrupada, con el caché deshabilitado , para obtener todas las preguntas de StackOverflow etiquetadas con 'android' en el mes de enero de 2018.
SELECCIONE
carné de identidad,
título,
cuerpo,
accept_answer_id,
fecha de creación,
answer_count,
Recuento de comentarios,
cuenta_favorita,
conteo de visitas
DE
`stackoverflow.questions_2018_clustered`
DÓNDE
fecha_creación ENTRE '2018-01-01'
Y '2018-02-01'
Y etiquetas = 'android';
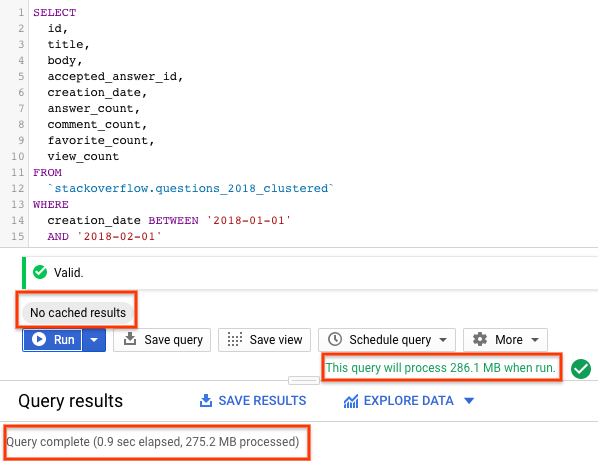
Con una tabla particionada y agrupada, la consulta escaneó ~ 275 MB de datos en menos de 1 s, lo que es mejor que una tabla particionada. La forma en que se organizan los datos mediante particiones y agrupaciones minimiza la cantidad de datos escaneados por los trabajadores de tragamonedas, lo que mejora el rendimiento de las consultas y optimiza los costos.
Algunas cosas a tener en cuenta al usar la agrupación en clústeres:
- La agrupación en clústeres no ofrece garantías de costes estrictas antes de ejecutar la consulta. Observe que en los resultados anteriores con la agrupación en clústeres, la validación de consultas informó un procesamiento de 286,1 MB, pero en realidad la consulta procesó solo 275,2 MB de datos.
- Utilice la agrupación en clústeres solo cuando necesite más granularidad de la que permite la creación de particiones.
Obtenga más información sobre cómo trabajar con tablas agrupadas aquí .
¿Qué sigue?
En este artículo, aprendimos cómo BigQuery organiza y administra el almacenamiento que contiene los datos, cómo puedes mejorar el rendimiento de las consultas mediante la partición y el agrupamiento de las tablas, y cómo puedes retener datos en BigQuery con precios de almacenamiento a largo plazo para datos inactivos.
- Vea la demostración sobre creación de particiones y agrupación en clústeres con BigQuery
- Aprenda a utilizar la agrupación en clústeres y la partición
- Codelab para probar la creación de particiones y agrupaciones en clústeres de BigQuery en su zona de pruebas de BigQuery
En la próxima publicación, veremos cómo puede ingerir datos en BigQuery y analizar los datos.
Manténganse al tanto. ¡Gracias por leer! ¿Tienes alguna pregunta o quieres charlar? Encuéntrame en Twitter o LinkedIn .
Gracias a Yuri Grinshsteyn y Alicia Williams por ayudarnos con la publicación.
Explicación de BigQuery: Storage Overview se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación destacando y respondiendo a esta historia.