He dedicado bastante tiempo a definir y configurar SLO en Service Monitoring. Y últimamente, he recibido muchas preguntas sobre lo que sucede a continuación: una vez que se configura el SLO, la gente quiere saber cómo usar las alertas para recibir notificaciones sobre violaciones de SLO potenciales, inminentes y en curso. Service Monitoring proporciona alertas de quema de presupuesto de errores de SLO para lograr precisamente eso, pero el uso de estas alertas no siempre es intuitivo. Me propuse probarlos por mí mismo y documentar lo que encontré en el camino. ¡Veamos qué pasa!
En teoria…
El Libro de trabajo de SRE tiene un capítulo completo dedicado a alertar sobre SLO. No creo que necesite reproducirlo aquí, pero hay dos clases de consideraciones que son muy importantes:
- ¿Cuál es la relación entre su alerta y la cantidad de eventos SLO que experimenta su servicio?
- La precisión es su tasa de verdaderos positivos: ¿qué fracción de sus alertas indicará realmente un evento que necesita conocer?
- El recuerdo es su "sensibilidad": ¿qué fracción de sus eventos generará una alerta?
- ¿Cuál es la relación entre una alerta y el evento que la desencadenó?
- El tiempo de detección es el tiempo entre el inicio del evento y el momento en que se activa la alerta.
- El tiempo de reinicio es el tiempo entre el final del evento y el momento en que se reinicia la alerta
Como puede imaginar, su SLO en sí Y la alerta que configure pueden afectar a todos estos. Es imposible optimizar todos estos (precisión de conducción y recuperación al 100% Y tiempo de detección y restablecer el tiempo a cero) Y no ahogarse en alertas, la mayoría de las cuales no serán procesables. Al mismo tiempo, no es práctico esperar hasta que se agote el presupuesto de error para alertar; es necesario avisar con anticipación para poder tomar las medidas adecuadas para garantizar que el servicio se mantenga dentro de su presupuesto de error diario / semanal / mensual. La forma de llegar es alertar sobre la quema del presupuesto de errores , en lugar de si su servicio está dentro del SLO durante un período breve específico.
La siguiente pregunta obvia: ¿qué porcentaje del presupuesto de errores debe consumirse antes de activar una alerta? El enfoque más avanzado recomendado en el capítulo del libro de trabajo de SRE es usar alertas de múltiples ventanas y múltiples tasas de quemado (consulte la sección 6). Pero para empezar, me gusta mucho la idea de dos alertas separadas con diferentes tasas de quemado, siguiendo la recomendación de “2% de quemado en 1 hora y 5% de quemado en 6 horas”.
Finalmente, y esta es la parte difícil, ¿cómo se identifica la velocidad de combustión exacta y la ventana de alerta para llegar al nivel de precisión y el tiempo de restablecimiento que necesita mientras se minimiza la sobrecarga operativa (respondiendo a alertas innecesarias) para su servicio? Del libro:
“Para las alertas basadas en la velocidad de combustión, el tiempo que tarda una alerta en un incendio es:
tiempo para disparar = (1-SLO) / tasa de error * tamaño de la ventana de alerta * tasa de quemado
El presupuesto de error consumido cuando se activa la alerta es:
presupuesto consumido = tasa de quema * tamaño / período de la ventana de alerta "
Veamos un ejemplo para aclarar esto. Supongamos que tiene un SLO de disponibilidad del 99,9% durante una ventana móvil de 28 días. Le gustaría recibir una alerta si consumió el 1% de su presupuesto de errores en la hora anterior. Eso significa que desea que la alerta se active si la tasa de error durante la última hora es mayor que el presupuesto objetivo * (1-SLO) * (período / ventana).
Sin embargo, Service Monitoring no le permite especificar una tasa de error; en su lugar, debe proporcionar un umbral de tasa de quemado . La tasa de quema es la tasa a la que su servicio consume el presupuesto de errores. Si la tasa de quema es 1.0, al final del período de evaluación de SLO, habrá consumido exactamente el 100% de su presupuesto de errores. Si la tasa de quema es 2.0, entonces al final del período habrá consumido el 200% de su presupuesto de errores (o habrá consumido todo su presupuesto de errores a la mitad del período de evaluación), y así sucesivamente. Usando la ecuación anterior para calcular la velocidad de combustión, obtenemos
tasa de quema = presupuesto consumido * período / ventana de alerta
En nuestro ejemplo:
- SLO = 99,9% o 0,999
- Tamaño de la ventana de alerta = 1 hora
- Presupuesto consumido = 1% o .01
- Periodo = 28 días o 672 horas
Esto significa que
velocidad de combustión = .01 * 672/1 = 6.72
Si configuramos nuestra alerta para que tenga un período de retroceso de 60 minutos y un umbral de velocidad de combustión de 6,72, podemos calcular la rapidez con la que obtendríamos una alerta en función de la tasa de error que experimenta nuestro servicio. Por ejemplo, si nuestra tasa de error sube al 1%, tiempo de disparo = (1-.999) / .01 * 1 * 672 = 67,2 horas, que son casi 3 días, ¡esta es una alerta con poca recuperación!
Si queremos mejorar nuestra recuperación y que la alerta se dispare justo en 1 hora, calculamos la velocidad de combustión usando 1 = (1-.999) / .01 * 1 * velocidad de combustión, lo que significa que la velocidad de combustión = 10. Para confirmar - tiempo para disparar = (1-.999) / .01 * 1 * 6.72 = 1! Nuestra alerta se disparará en exactamente una hora.
En la práctica…
Quería considerar el uso de Service Monitoring para implementar un enfoque más simple (como se describe en la sección 5): dos alertas separadas con diferentes tasas de quemado, siguiendo la recomendación de “2% de quema en 1 hora y 5% de quema en 6 horas”.
La puesta en marcha
Servicio y SLO
Para empezar, necesitaba una aplicación simple cuya tasa de error pudiera controlar con precisión sin volver a implementar el código. Puedes ver el código del servicio aquí . Es una aplicación Node.js Express bastante básica que escribe entradas de registro para cada solicitud y falla. Luego configuré métricas basadas en registros para contar ambos. Configuré un servicio usando la interfaz de usuario:
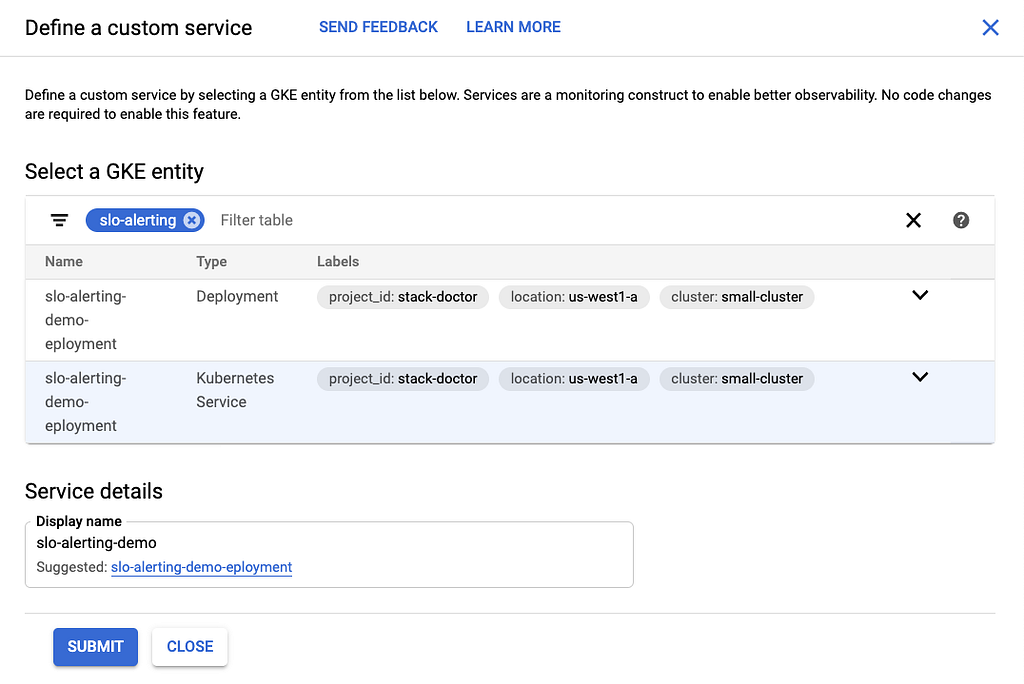
A continuación, necesitaba definir el SLO. Debido a que mi servicio utiliza dos métricas diferentes para los filtros "bueno" y "malo", no pude averiguar cómo crear un SLO de este tipo en la interfaz de usuario. Como tal, necesitaba usar la API; aquí está la llamada a la API:
Esto creó un SLO para "95% de disponibilidad durante un período continuo de 28 días". Aquí está en la interfaz de usuario:
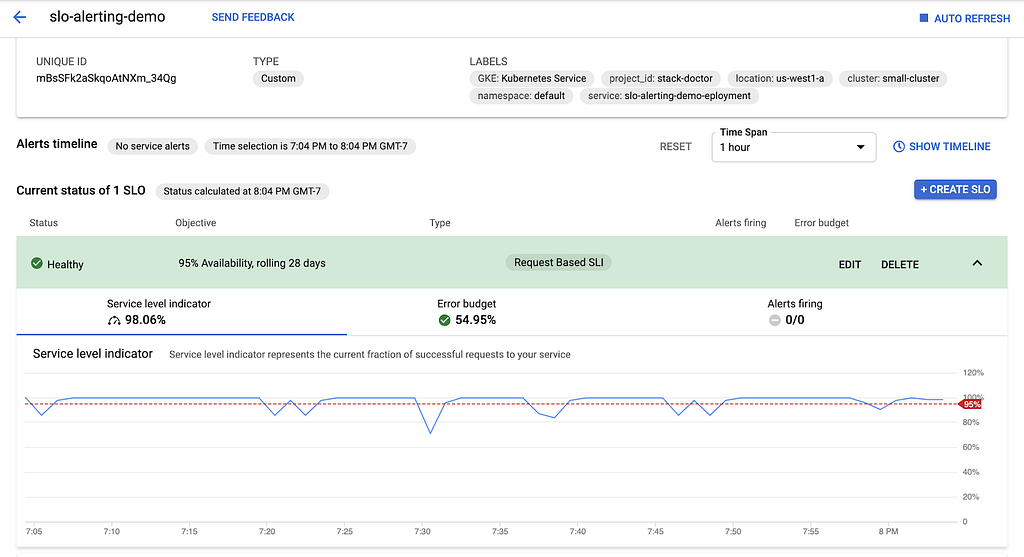
Inyección de fallas
A continuación, necesitaba inyectar una tasa de error deseada en el servicio para poder validar que el aumento de la tasa de error daría como resultado una quema del presupuesto de errores y activaría alertas. Después de una discusión interna, identifiqué un par de opciones:
- Usando las capacidades de inyección de fallas de Istio
- Hacer que mi aplicación lea una variable de entorno que podría ser administrada por un ConfigMap
Decidí usar este último. Puedes ver mi código aquí ; la esencia es que utilicé el proceso de Node.ENV.
Alertas
Finalmente, estaba listo para configurar mis alertas. Como se discutió anteriormente, quería probar dos alertas:
- Consumo de presupuesto de error del 2% en 1 hora
- 5% de quemado del presupuesto de error en 6 horas
Como se mencionó en la sección "teoría", Service Monitoring espera dos entradas para las alertas de quemado del presupuesto de errores: una duración al pasado y un umbral de velocidad de quemado:
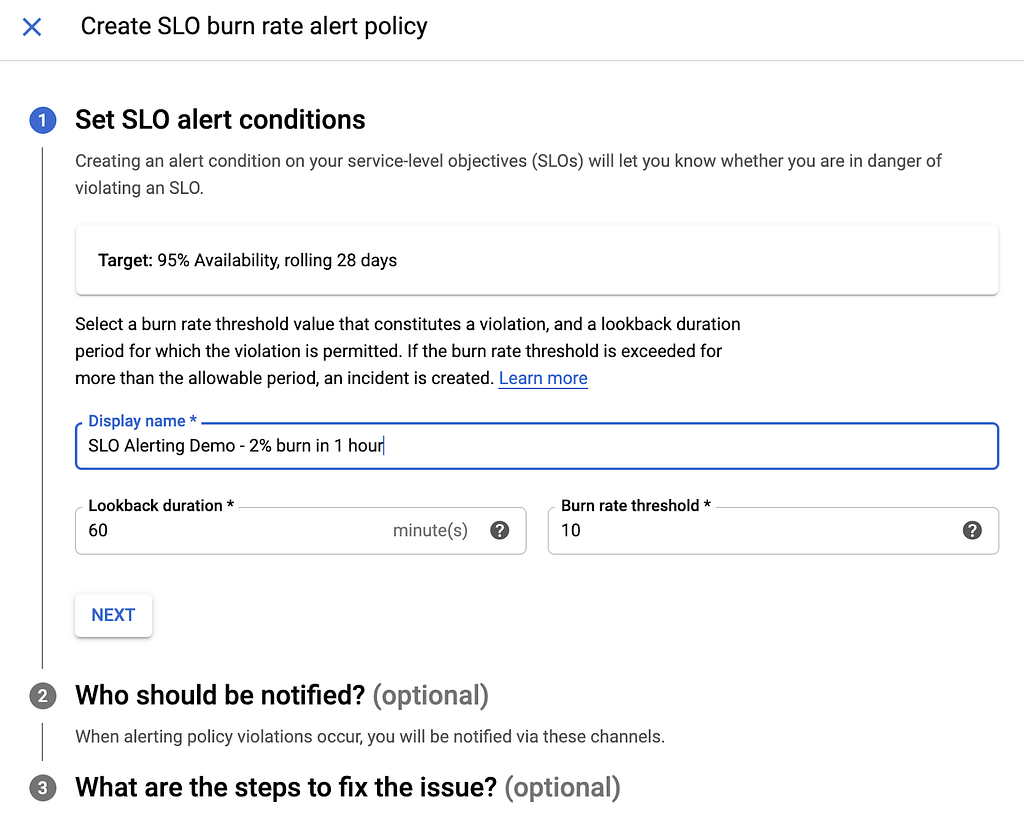
Como sabía que quería monitorear el consumo de presupuesto de errores durante una hora, la duración de la conversión fue una decisión fácil: lo configuré en 60 minutos. Sin embargo, necesitaba calcular mi umbral de velocidad de combustión. Ya mostré cómo lo calculé para el ejemplo de quemado del “1% en 1 hora”. Esta vez, mis entradas fueron las siguientes:
- Tamaño de la ventana de alerta = 1 hora
- Presupuesto consumido = 2% o 0,02
- Periodo = 28 días o 672 horas
Para calcular la velocidad de combustión, usé
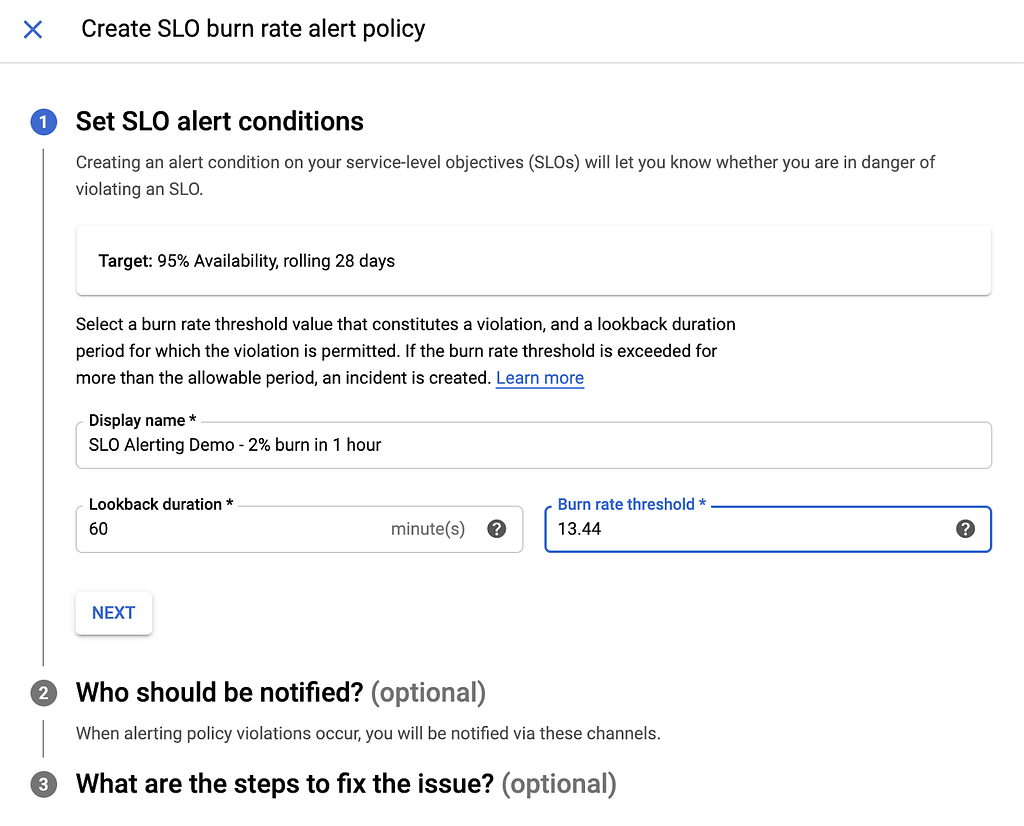
tasa de quema = presupuesto consumido * período / ventana de alerta = .02 * 672/1 = 13.44
Este es el umbral de velocidad de combustión que espera nuestra política de alertas:
A continuación, necesitaba calcular el umbral de velocidad de combustión para la alerta "5% de presupuesto de error quemado en 6 horas". Esta vez:
- Tamaño de la ventana de alerta = 6 horas
- Presupuesto consumido = 5% o .05
- Periodo = 28 días o 672 horas
Lo que significa que
tasa de quema = presupuesto consumido * período / ventana de alerta = .05 * 672/6 = 6.72:
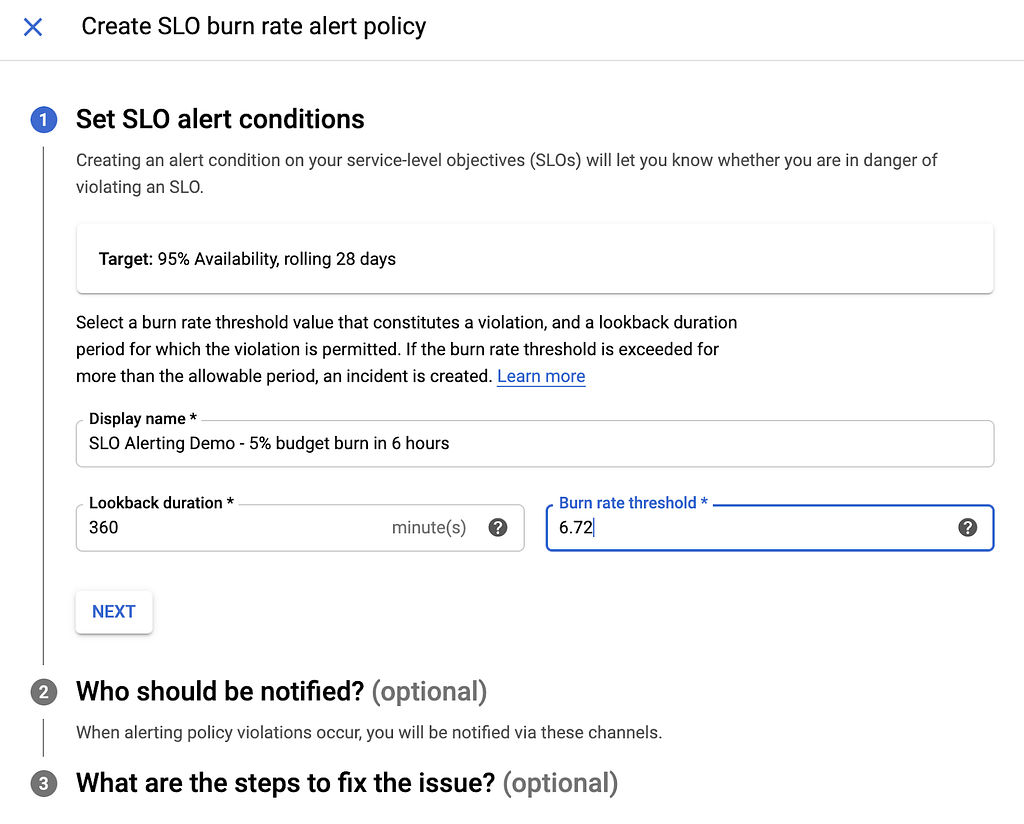
Ahora, mis dos alertas estaban listas para funcionar. Estaba listo para introducir errores en el servicio y probar las alertas.
Prueba de alertas
La primera pregunta que tenía que responder era: ¿cuál debería ser la tasa de error para activar la alerta en un período de tiempo razonable? Como se discutió anteriormente:
tiempo para disparar = (1-SLO) / tasa de error * tamaño de la ventana de alerta * tasa de quemado
Esto hace
tasa de error = (1 - SLO) * tamaño de la ventana de alerta * tasa de quemado / tiempo para disparar
Para la primera alerta, mis valores fueron los siguientes:
- Tiempo deseado para disparar = 1 hora
- SLO = 95% o 0,95
- Tamaño de la ventana de alerta = 1 hora
- Tasa de quema = 13,44
Esto significaba que mi índice de error debería ser de al menos 0,672 o 67,2%, ¡eso es bastante alto! Recreé el mapa de configuración con ese valor y eliminé el pod, que la implementación recreó automáticamente. Casi de inmediato, vi una disminución en mi SLI:
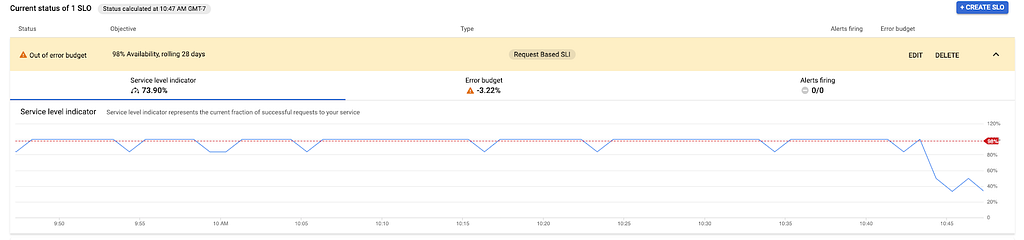
Debido a que configuré mi SLO más alto de lo que pretendía, el servicio ya estaba fuera del presupuesto de error, pero la caída inmediata fue exactamente lo que esperaba. Mi servicio tampoco se había estado ejecutando durante un mes completo, por lo que pensé que la alerta se dispararía mucho más rápido que mi cálculo, porque en realidad no había acumulado suficiente presupuesto de error en este punto, y grabar el 2% no tomaría tiempo en todos.
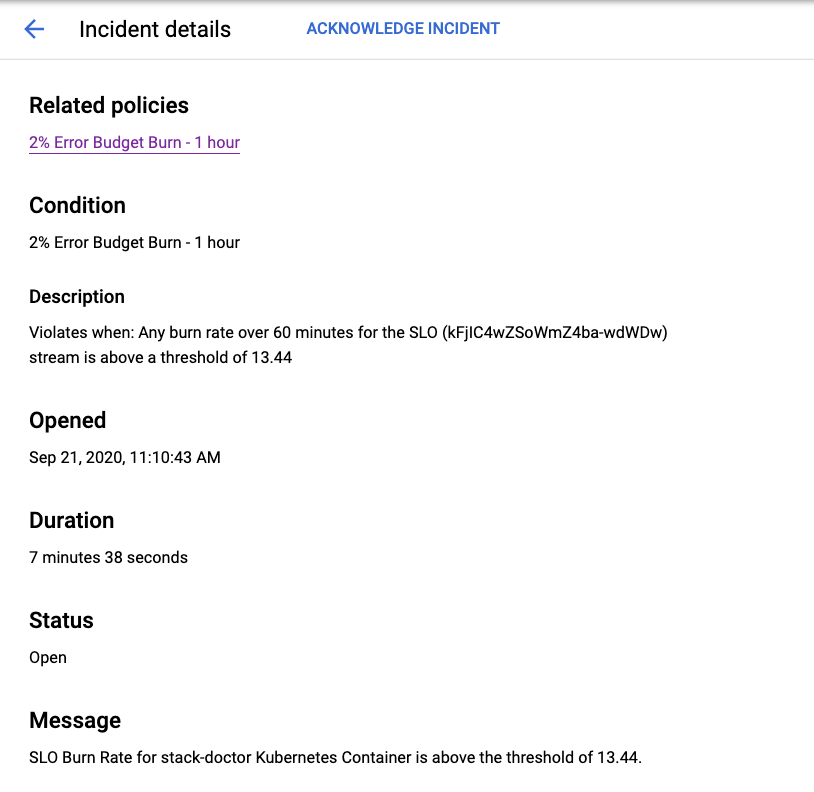
Efectivamente, pronto vi que la tasa de quemado del presupuesto de error cruzaba el umbral:

Y la alerta generó:
Terminando…
Estoy muy contento de haberme tomado el tiempo para resolver esto Y documentar mi viaje a lo largo del camino, y espero que esto le sea útil. En particular, descubrí que no hay mucha información disponible sobre qué es exactamente una tasa de quemado de presupuesto de error en la documentación del producto, y fue necesario investigar un poco para comprender realmente las matemáticas necesarias para calcularla. Sin embargo, me gusta mucho este enfoque para configurar alertas en SLO. Gracias por leer, ¡y hágame saber lo que piensa!
Cómo alertar sobre SLO se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.