(Una prueba y sus resultados)
Introducción
Las organizaciones usan Google Dataflow para procesar y enviar los datos a los dispositivos de IoT para controlarlos o monitorearlos. Los diferentes casos de uso requieren diferentes latencias. Esta prueba intenta tener una idea de cuánto tiempo le toma a Google Dataflow seleccionar y comenzar a procesar cada elemento de Pub / Sub, en el entorno de prueba dado.
Descargo de responsabilidad rápido: de ninguna manera se trata de una evaluación de referencia.
Resumen de la prueba
Pasos de prueba:
- Cree un tema de Pub / Sub y envíe datos al tema como datos de transmisión simulados. El contenido de los datos es la marca de tiempo de cuando se publica el mensaje.
- Dataflow lee de Pub / Sub, procesa cada elemento y escribe la marca de tiempo del proceso en BigQuery. Si no desea escribir en BigQuery directamente, puede escribir en el registro de StackDriver y crear un receptor para el registro más tarde.
- Para calcular la latencia, ejecute una consulta en BigQuery para ver la diferencia horaria.
Entorno de prueba: Python.
Arquitectura de prueba:

Pruebe los pasos detallados:
- Si no ha configurado el entorno de ejecución de Python para ejecutar trabajos de Dataflow, consulte este enlace y configúrelo.
2. Envíe datos de transmisión simulada a un tema de Pub / Sub:
# crea un tema de prueba
Los temas de gcloud pubsub crean TOPIC_NAME
# usar el programador de gcloud para ejecutar el trabajo del editor cada segundo (datos de transmisión simulados) que contienen la marca de tiempo cuando se ejecuta el trabajo de publicación
Los trabajos del programador de gcloud crean pubsub publisher-job \
- horario = "* * * * *" \
- tema = TOPIC_NAME - cuerpo del mensaje = `fecha +% s`
3. Dataflow procesa y registra información en BigQuery:
Para registrar a qué hora se recogió el elemento de datos de Pub / Sub, guardamos el valor de beam.DoFn.TimestampParam .
clase LatencyFn (haz.DoFn):
def proceso (self, element, publish_time = beam.DoFn.TimestampParam):
rendimiento {
"msg_publish_time": json.loads (elemento),
"msg_process_time": round (time.mktime (dt.datetime.now (). timetuple ()))
}
Luego, escriba la información de tiempo en una tabla de BigQuery. El fragmento está en lo siguiente:
def ejecutar (input_topic, output_topic, pipeline_args = None):
pipeline_options = PipelineOptions (
pipeline_args, streaming = True, save_main_session = True
)
con beam.Pipeline (opciones = pipeline_options) como p:
msg = (p | "ReadPubSubMsg" >>
beam.io.ReadFromPubSub (tema = input_topic)
| "GetMsgInfo" >> haz.ParDo (LatencyFn ())
)
msg | 'WriteBQ' >> beam.io.WriteToBigQuery (
table = 'test.test_latency_info',
esquema = 'msg_publish_time: STRING,
msg_process_time: STRING ',
create_disposition =
beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition =
beam.io.BigQueryDisposition.WRITE_APPEND
)
...
4. Implemente el trabajo de flujo de datos desde la consola.
python test.py - proyecto = PROJECT_NAME - nombre_trabajo = prueba - input_topic = proyectos / PROJECT_NAME / topics / TOPIC_NAME - corredor = DirectRunner
5. Una vez que Dataflow comience a ejecutarse, leerá cada mensaje de Pub / Sub y escribirá la información de tiempo en la tabla de BigQuery.
6. Vaya a BigQuery y analice los datos registrados en una consulta como:
SELECCIONE
MIN (latencia) como min,
MAX (latencia) como máximo,
approx_quantiles (latencia, 100) [desplazamiento (50)] como p50,
approx_quantiles (latencia, 100) [desplazamiento (90)] como p90,
approx_quantiles (latencia, 100) [desplazamiento (99)] como p99
DE
(SELECT cast (msg_process_time como int64) - cast (msg_publish_time como int64) AS latencia
FROM `PROJECT_ID.DATASET_ID.TABLE_ID`)
Resultado de la prueba:
Desde el momento en que Cloud Scheduler envió datos a Pub / Sub, hasta el momento en que Pub / Sub procesó el elemento de datos, la consulta anterior muestra el siguiente resultado en milisegundos:
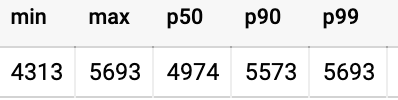
Para presentar la información, podemos agregar la información de latencia a (digamos) Data Studio, para visualización y profundización. Ayuda a identificar visualmente picos de latencia inusuales.
Este flujo podría ampliarse a tantos pasos de procesamiento de Dataflow como sea posible.
¿Cuánto tiempo selecciona y procesa Google Dataflow los mensajes Pub / Sub en "tiempo real"? se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación destacando y respondiendo a esta historia.