Spanner es una base de datos distribuida que Google inició hace un tiempo para construir una base de datos altamente disponible y altamente consistente para sus propias cargas de trabajo. Inicialmente, Spanner se creó para ser una clave / valor y estaba en una forma completamente diferente de lo que es hoy y tenía objetivos diferentes. Desde el principio, tenía capacidades transaccionales, consistencia externa y fue capaz de realizar una conmutación por error transparente. Con el tiempo, Spanner adoptó un esquema fuertemente tipado y algunas otras características de bases de datos relacionales. En los últimos años, agregó soporte SQL *. Hoy estamos mejorando tanto el dialecto SQL como las características de la base de datos relacional simultáneamente. A veces hay confusión sobre si Spanner admite SQL o no. La respuesta corta es sí. La respuesta larga es este artículo.
Primeros años
Spanner se creó inicialmente para cargas de trabajo internas y nadie pudo ver que Google iniciará un negocio en la nube y externalizará Spanner. Si no sabe mucho sobre Google, nuestra pila interna a menudo se considera como un universo diferente. En Google, todos los sistemas, incluidos los servicios de almacenamiento y base de datos, proporcionan sus propias API y clientes patentados. ¿Planeas usar tu biblioteca ORM favorita cuando te unas a Google? Lamentablemente, no es posible. Nuestros servicios de infraestructura proporcionan sus propias API Stubby / gRPC y bibliotecas de clientes. Esta es una desventaja menor si le preocupa la familiaridad con la API, pero es un diferenciador fuerte porque podemos proporcionar API más expresivas que representan las características diferenciadas de nuestra infraestructura.
Las características diferenciadas a menudo están mal representadas en las API comunes. Una talla no sirve para todos. Las API comunes solo pueden apuntar a las características comunes. Las bases de datos distribuidas ya son muy diferentes a las bases de datos relacionales tradicionales. Daré dos ejemplos en este artículo para mostrar cómo las API explícitas marcan la diferencia.
Los sistemas distribuidos fallan de manera diferente y con mayor frecuencia. Para resolver este problema, los sistemas distribuidos implementan mecanismos de reintento. Los clientes de Spanner reintentan las transacciones de forma transparente cuando no las confirmamos. Esto nos permite no mostrar cada falla temporal al usuario. Intentamos transparentemente con la estrategia de retroceso correcta.
En el siguiente fragmento, verá un código Go que inicia una nueva transacción de lectura y escritura. Toma una función donde puede consultar y manipular datos. Cuando hay un aborto o conflicto, reintenta la función automáticamente. ReadWriteTransaction documenta este comportamiento y documenta que la función debería ser segura para volver a intentar (por ejemplo, decirle a los desarrolladores que no tienen el estado de la aplicación). Esto nos permite comunicar la realidad única de las bases de datos distribuidas al usuario. También podemos proporcionar capacidades como reintentos automáticos que son más difíciles de implementar en ORM tradicionales.
importar "cloud.google.com/go/spanner"
_, err: = client.ReadWriteTransaction (ctx, func (ctx context.Context, txn * spanner.ReadWriteTransaction) error {
// Código de usuario aquí.
}) Otro ejemplo son los niveles de aislamiento. Spanner implementa un nivel de aislamiento mejor que el nivel de aislamiento más estricto (serializable) descrito en el estándar SQL. Spanner no le permite elegir nada menos estricto para las transacciones de lectura / escritura. Pero para configuraciones multirregionales y transacciones de solo lectura, proporcionar el aislamiento más fuerte no siempre es factible. Nuestros límites son probados por la velocidad de la luz. Para los usuarios que están bien con datos ligeramente obsoletos, Spanner tiene capacidades para proporcionar lecturas obsoletas. Las lecturas obsoletas permiten a los usuarios leer la versión disponible en la réplica regional. Pueden establecer cuánta caducidad pueden tolerar. Por ejemplo, la transacción a continuación puede tolerar hasta 10 segundos.
importar "cloud.google.com/go/spanner"
client.ReadOnlyTransaction ().
WithTimestampBound (spanner.MaxStaleness (10 * time.Second)).
Consulta (ctx, consulta)
Staleness API nos permite expresar explícitamente cómo funciona el aislamiento de instantáneas y cómo Spanner puede ir y obtener los últimos datos si la réplica está muy desactualizada. También nos permite destacar cómo la replicación multirregional es un problema difícil e incluso con una base de datos como Spanner, puede considerar comprometer la coherencia para obtener mejores características de latencia en una configuración multirregional.
F1
F1 fue el experimento original para los primeros pasos para tener soporte SQL en Spanner. F1 es una base de datos distribuida en Google que está construida sobre Spanner. A diferencia de Spanner, soportaba:
- Consultas SQL distribuidas
- Índices secundarios transaccionalmente consistentes
- Cambiar historial y transmisión
Implementó estas características en una capa de coordinación sobre Spanner y entregó todo lo demás a Spanner.
F1 se creó para admitir nuestros productos de anuncios. Dada la naturaleza del negocio de anuncios y la complejidad de nuestros productos de anuncios, fue fundamental poder escribir y ejecutar consultas complejas. F1 hizo que Spanner fuera más accesible para los sistemas pesados de lógica empresarial.
Llave en la nube
Avance rápido, Google Cloud lanzó Spanner para nuestros clientes externos. Cuando se lanzó por primera vez, solo tenía soporte de SQL para consultar datos. Carecía de las instrucciones INSERT, UPDATE y DELETE.
Dado que no tenía una base de datos SQL en ese momento, también carecía de soporte de controladores para JDBC , base de datos / sql y similares. El soporte de controladores se convirtió en una posibilidad cuando Cloud Spanner implementó un soporte de lenguaje de manipulación de datos (DML) para inserciones, actualizaciones y eliminaciones.
Hoy, Cloud Spanner admite tanto DDL (para esquema) como DML (para datos). Cloud Spanner utiliza un dialecto SQL utilizado por Google. ZetaSQL , un analizador y analizador nativo de este dialecto, ha abierto fuentes hace un tiempo. A partir de hoy, Cloud Spanner también proporciona una herramienta de análisis de consultas.
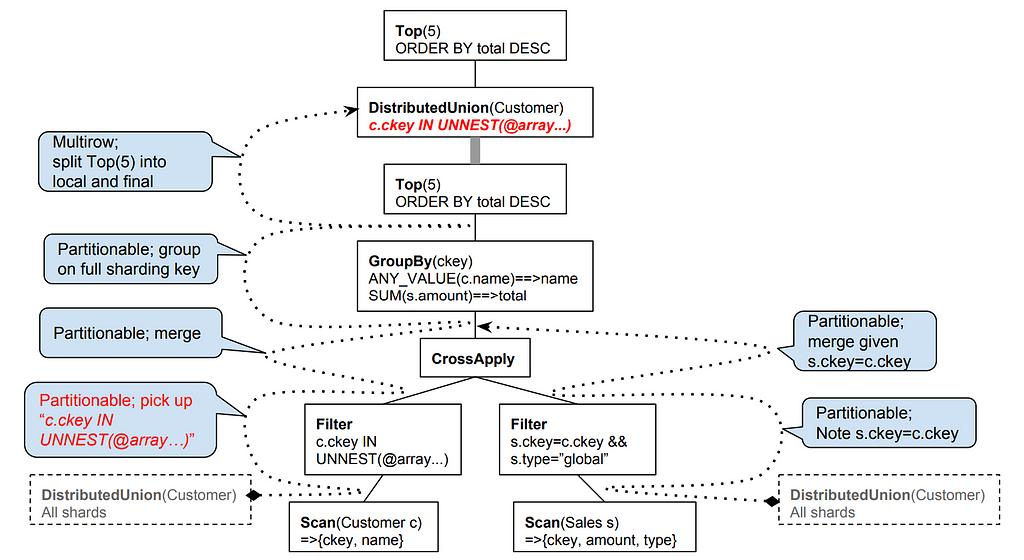
¿Próximo?
Existen desafíos actuales originados por las diferencias presentes en nuestro dialecto SQL. Esta es un área que estamos tratando activamente de mejorar. No solo no queremos que nuestros usuarios se ocupen de una nueva versión de SQL, sino que la situación actual también está ralentizando nuestro trabajo en las integraciones de ORM. Algunos de los marcos de ORM codifican el SQL al generar consultas y dan a los conductores poca flexibilidad para anular el comportamiento. Para evitar inconsistencias, estamos tratando de cerrar las diferencias con los dialectos populares.
Las diferencias de dialecto no son el único problema que afecta nuestro soporte de SQL. Otro vacío importante es la falta de algunas de las características comunes de la base de datos tradicional. Spanner nunca admitió características como valores predeterminados o ID autogenerados. A medida que mejoramos las diferencias de dialecto, siempre está en nuestro radar abordar simultáneamente estas brechas significativas.
-
(*) El trabajo inicial sobre el trabajo de consulta de Spanner se publica como Spanner: Convertirse en un sistema SQL .
La historia SQL de Spanner se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.