Al entrenar un modelo de red neuronal, el tiempo es esencial. Esta es la razón por la cual se utilizan diferentes configuraciones de máquina, incluidas GPU, TPU y múltiples servidores.
He estado explorando el proyecto YouTube-8M durante los últimos dos meses y hay publicaciones anteriores sobre el proyecto, el conjunto de datos de video, los algoritmos y cómo ejecutarlos en la nube. Para esta publicación, entrené los dos algoritmos del código de inicio en diferentes configuraciones de máquina estándar de la Plataforma AI para ver cómo se compararon. AI Platform proporciona una serie de niveles de escala que son configuraciones establecidas de diferentes tipos de máquinas y cantidad de máquinas para ejecutar trabajos.
La publicación cubre cómo ejecutar los diferentes niveles de escala y las comparaciones de tiempo y costo de cómo ambos algoritmos, la regresión logística a nivel de cuadro y la bolsa profunda de modelos de cuadro, lo hicieron en los diferentes niveles y tipos.
Banderas de línea de comando
El proyecto YouTube-8M incluye un archivo yaml en el repositorio de código de inicio para establecer la configuración de este proyecto cuando se ejecuta en la plataforma AI. Puede modificar este archivo cada vez para cambiar los niveles o puede hacer algo más fácil que es pasar banderas que cambien los niveles (--scale-tier) y los tipos (--master-machine-type).
Hay un par de formatos diferentes sobre cómo pasar en el nivel de escala
--scale-tier = 'BASIC_TPU'
--scale-tier = basic-tpu
Al pasar banderas para el nivel de escala, debe especificar --runtime-version; de lo contrario, obtendrá un error:
"La versión de tiempo de ejecución se debe proporcionar cuando el URI maestro de la imagen de Docker está vacío".
Use lo siguiente para este proyecto.
--runtime-version = 1.14
Niveles de escala
Experimenté ejecutando los 2 algoritmos diferentes, Logística a nivel de cuadro y Deep Bag of Frames (DBoF), en el código de inicio en los siguientes niveles de escala.
- STANDARD_1 : 1 maestro con 8 VCPU | 8 GB de memoria, 4 trabajadores con 8 VCPU | 8 GB de memoria y 3 servidores de parámetros con 4 VCPU | 15 GB de memoria
- PREMIUM_1 : 1 maestro con 16 VCPU | 14,4 GB de memoria, 4 trabajadores con 16 VCPU | 14,4 GB de memoria y 3 servidores de parámetros con 8 VCPU | 52GB de memoria
- BASIC_GPU: 1 trabajador con 1 GPU K80 | 8 VCPU | 30 GB de memoria
- BASIC_TPU : 1 maestro con 4 VCPU | Memoria de 15 GB y 8 núcleos TPU v2
- PERSONALIZADO : Más información a continuación
Código de ejemplo al pasar los indicadores de nivel de escala
JOB_NAME = yt8m_train_frame _ $ (fecha +% Y% m% d_% H% M% S)
gcloud --verbosity = depurar trabajos de plataforma ai enviar entrenamiento \
$ JOB_NAME --package-path = youtube-8m --module-name = youtube-8m.train \ --staging-bucket = $ OUTPUT_BUCKET \
--scale-tier = basic-tpu --runtime-version = 1.14 --region = us-central1 \
- --train_data_pattern = '$ TRAIN_BUCKET / train * .tfrecord' \
--frame_features --model = FrameLevelLogisticModel \
--feature_names = "rgb, audio" --feature_sizes = "1024,128" \
--train_dir = $ OUTPUT_BUCKET / $ JOB_NAME --start_new_model
CPU solamente
Tenga en cuenta que la publicación anterior sobre cómo ejecutar este proyecto en la Plataforma AI cubrió la ejecución del equivalente de BASIC_GPU. El uso de STANDARD_1 y PREMIUM_1 no tenía suficiente memoria para ejecutar los modelos. Puede considerar usar una configuración personalizada que le permita aumentar la memoria maestra y de trabajo. Además, para señalar que en publicaciones anteriores ejecuté estos modelos en un solo servidor con solo CPU con al menos 30 GB de memoria y pude ejecutar Frame-level pero no DBoF. Es posible que pueda encontrar una configuración de múltiples trabajadores que ejecute DBoF con solo CPU, pero al final, tiene sentido usar TPU y GPU al entrenar una red neuronal.
GPU
AI Platform le da acceso a 3 tipos diferentes de GPU para configuraciones de máquina. Los niveles de escala estándar solo incluyen K80, y debe usar un nivel personalizado para utilizar los demás. Estos son los diferentes tipos de GPU en orden creciente de su rendimiento.
- K80
- p100
- v100
La complejidad del modelo y la cantidad de datos influirán en la cantidad de ganancias de rendimiento que obtendrá al agregar estos diferentes tipos de GPU.
Acceso TPU
El nivel de escala de TPU es una forma rápida de obtener acceso a TPU para su proyecto. Al solicitar TPU, debe especificar una región; de lo contrario, puedes dejarlo. Puede obtener el siguiente error si no elige una región en la que el sistema tenga TPU:
" RESOURCE_EXHAUSTED Ninguna zona en la región us-west1 tiene aceleradores de todos los tipos solicitados".
Cuando dejé la región, por defecto us-west1 y mirando la lista de tipos y zonas de TPU, parece que está basada en la región us-central1 . Puede encontrar una lista de tipos y zonas de TPU en este enlace .
Niveles personalizados
Los niveles personalizados son exactamente como suenan, proporcionan flexibilidad en la configuración de la máquina.
Al usar el nivel de escala personalizado, debe pasar el tipo maestro-máquina.
--master-machine-type = [ OPCIONES DE TIPO DE MÁQUINA ]
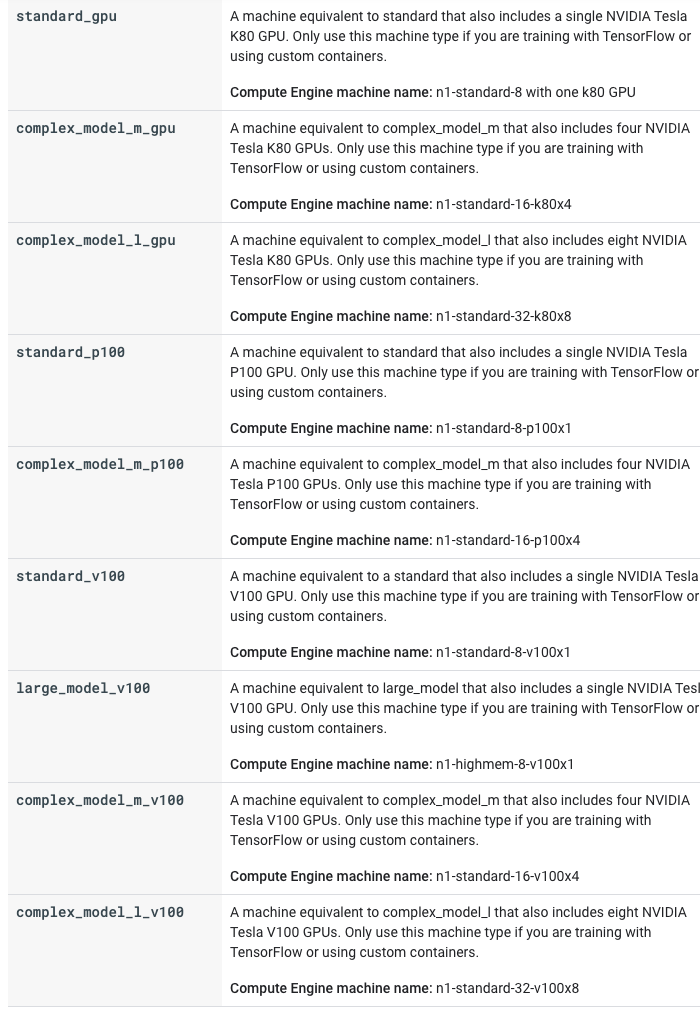
Opciones de tipo de máquina que utilicé.
- complex-model-m-gpu : 4 GPU K80 | 8 VCPU | 30 GB de memoria
- complex-model-l-gpu : 8 GPU K80 | 16 VCPU | 60 GB de memoria
- estándar-p100 : 1 GPU P100 | 8 VCPU | 30GB de memoria
- complex-model-m-p100 : 4 GPU P100 | 16 VCPU | 60 GB de memoria
- estándar-v100 : 1 GPU V100 | 8 VCPU | 30 GB de memoria
- large-model-v100 : 1 GPU V100 | 16 VCPU | 52 GB de memoria
Código de ejemplo al pasar el nivel personalizado y los indicadores de tipo de máquina.
JOB_NAME = yt8m_train_frame _ $ (fecha +% Y% m% d_% H% M% S)
gcloud --verbosity = depurar trabajos de plataforma ai enviar entrenamiento \
$ JOB_NAME --package-path = youtube-8m --module-name = youtube-8m.train \ --staging-bucket = $ OUTPUT_BUCKET \
--scale-tier = custom --master-machine-type = standard_p100 \
--runtime-version = 1.14 \
- --train_data_pattern = '$ TRAIN_BUCKET / train * .tfrecord' \
--frame_features --model = FrameLevelLogisticModel \
--feature_names = "rgb, audio" --feature_sizes = "1024,128" \
--train_dir = $ OUTPUT_BUCKET / $ JOB_NAME --start_new_model
Tenga en cuenta que hay espacio para un control más detallado del tipo de máquinas, configuraciones y la posibilidad de agregar un número de trabajadores. Se puede encontrar más información en el enlace en la parte superior de la publicación. Me apegué a algunas configuraciones estándar para esta demostración y no agregué trabajadores más allá de lo que se proporcionó. Por lo tanto, se mantuvo en una sola máquina para la mayoría de los ejemplos y todos los ejemplos personalizados incluyen GPU.
Para obtener más detalles sobre las configuraciones, consulte la captura de pantalla a continuación y consulte los documentos :
Cuotas
A continuación se muestran las cuotas que se configuraron automáticamente para mi proyecto.
- 16 TPU_V2
- 16 TPU_V3
- 2 P4
- 2 V100
- 40 K80
- 40 P100
Descubrí esto en el error que recibí cuando intenté experimentar con un par de tipos de máquinas que tienen más de 2 V100. Si su trabajo requiere que escale las máquinas más que esto, entonces debe hacer una solicitud de aumento de cuota. Si tengo acceso a más de 2 V100 en el futuro cercano, ejecutaré esos otros tipos de máquinas y agregaré los detalles a continuación.
Comparación de rendimiento
Ahora, para la parte divertida, comparar el rendimiento de los dos algoritmos diferentes con todas estas configuraciones diferentes. Lo bueno de AI Platform y de cualquier servicio administrado es que puede activar todo esto a la vez y pueden ejecutarse en paralelo.
Un recordatorio de que el precio de los neumáticos de escala predefinidos es de $ .49 por hora por unidad de entrenamiento, que es el precio base. Para obtener el costo del trabajo, multiplique el precio base por la unidad ML consumida . Las unidades ML consumidas (MLU) son equivalentes a las unidades de entrenamiento con la duración del trabajo incluida.
El tiempo y el costo pueden variar ligeramente si intenta esto por su cuenta, pero deben estar dentro de un rango de minutos de lo que se proporciona a continuación.
Logística a nivel de trama
Cada punto de viñeta proporciona nivel de escala / tipo de máquina, tiempo total de entrenamiento y costo total.
- BASIC_GPU: 13 h 9 min y 21.85 MLU * $ .49 = $ 10.71
- BASIC_TPU : 20 h 51 min y 198.58 MLU * $ .49 = $ 97.31
- complex-model-m-gpu: 11 h 30 min y 59.27 MLU * $ .49 = $ 29.04
- complex-model-l-gpu : 11 hr 7 min y 114.72 MLU * $ .49 = $ 56.21
- estándar-p100 : 12 h 45 min y 47.39 MLU * $ .49 = $ 23.22
- complex-model-m-p100 : 11 hr 57 min y 159.61 MLU * $ .49 = $ 78.21
- estándar-v100 : 12 h 19 min y 71.39 MLU * $ .49 = $ 34.98
- large-model-v100 : 13 h 17 min y 79.28 MLU * $ .49 = $ 38.85
La configuración básica de la GPU es la mitad del costo de la siguiente opción de menor costo, estándar p100 , pero se tarda casi 30 minutos más en ejecutarse. Este es un gran ejemplo de determinar cuál es el valor del tiempo. ¿Puedes esperar 30 minutos para completar el entrenamiento? Probablemente. Aún así, cuando entrenes, lo más probable es que necesites ejecutar estas máquinas varias veces para ajustar y experimentar con el modelo. Ese tiempo extra puede sumar y puede parecer más rentable (especialmente teniendo en cuenta los plazos) usar una máquina que pueda ahorrar algo de tiempo.
Deep Bag of Frames (DBoF)
Cada punto de viñeta proporciona nivel de escala / tipo de máquina, tiempo total de entrenamiento y costo total.
- BASIC_GPU: 1 día 10 horas y 56.26 MLU * $ .49 = $ 27.57
- BASIC_TPU : se quedó sin memoria y salió con un estado distinto de cero
- complex-model-m-gpu: 1 día 4 horas y 145.95 MLU * $ .49 = $ 71.52
- complex-model-l-gpu : 1 día 3hr y 286.36 MLU * $ .49 = $ 140.32
- estándar-p100 : 16 h 59 min y 63.14 MLU * $ .49 = $ 30.94
- complex-model-m-p100 : 16 h 22 min y 219.11 MLU * $ .49 = $ 107.36
- estándar-v100 : 16 h 24 min y 92.8 MLU * $ .49 = $ 45.47
- large-model-v100 : 15 h 23 min y 91.76 MLU * $ .49 = $ 44.96
Para este modelo, está claro que el v100 GPUS fue un poco más rápido y puede ser casi tan rentable como el p100. que era casi tan rápido y la opción más barata al factorizar en el tiempo. Además, al agregar más GPU como en los modelos complejos, el costo aumentó significativamente pero el tiempo no mejoró tanto. En este caso de uso, una sola GPU hace el trabajo, pero hay otras situaciones basadas en limitaciones de modelo, datos y tiempo en las que se necesitan múltiples GPU.
También para señalar que si desea experimentar con TPU, cree un nivel personalizado que los use y use un main / master que tenga más memoria que la configuración BASIC_TPU (al menos 30 GB).
En general, para ambos modelos, las GPU v100 muestran un rendimiento sólido, pero la única p100 es la mejor opción cuando se consideran las compensaciones de tiempo y costo.
Envolver
Esta publicación se centró en revisar cómo los diferentes niveles de escala de la plataforma AI y los tipos de máquina se desempeñaron con los algoritmos de ejemplo YouTube-8M. Escalar el número de GPU, TPU y servidores depende de la complejidad de su modelo, la cantidad de datos y la cantidad de tiempo que tiene para hacer el trabajo. Esos lo ayudarán a determinar qué usar y usar varios servidores o GPU no es necesariamente más rápido. Es importante tomarse el tiempo para comprender sus requisitos antes de activar la plataforma.
Lo que mostró la publicación fue que para este proyecto específico y los dos algoritmos que proporciona el código, el nivel personalizado que usa el estándar-p100 fue la mejor opción considerando el tiempo y el costo. Si explora otros modelos, una configuración diferente puede satisfacer mejor sus necesidades. Además, no exploré exhaustivamente todas las formas en que puede personalizar estas configuraciones, por lo que puede haber una mejor opción. Te reto a que lo busques y avísame si lo encuentras.
La comparación de los tipos de máquina de la plataforma AI con YouTube-8M se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.