¿Cómo evita Spanner un único punto de falla en las escrituras?
Google's Spanner es una base de datos relacional con una disponibilidad del 99.999% que se traduce en 5 minutos de tiempo de inactividad al año. Spanner es un sistema distribuido y puede abarcar múltiples máquinas, múltiples centros de datos (e incluso regiones geográficas cuando está configurado). Divide los registros automáticamente entre sus réplicas y proporciona conmutación por error automática. A diferencia de los modelos de conmutación por error tradicionales, Spanner no realiza la conmutación por error a un clúster secundario, pero puede elegir una réplica de lectura y escritura disponible como el nuevo líder.
En las bases de datos relacionales, proporcionar tanto alta disponibilidad como alta consistencia en las escrituras es un problema muy difícil. La replicación síncrona de Spanner y el uso de redes dedicadas y votación de Paxos proporcionan alta disponibilidad sin comprometer la consistencia.
Alta disponibilidad de lecturas vs escrituras
En bases de datos relacionales tradicionales (por ejemplo, MySQL o PostgreSQL), escalar y proporcionar una mayor disponibilidad para las lecturas es más fácil que las escrituras. Las réplicas de solo lectura proporcionan una copia de los datos que las transacciones de solo lectura pueden recuperar. Los datos se replican en las réplicas de solo lectura desde un maestro de lectura y escritura de forma síncrona o asíncrona.
En modelos sincrónicos, el maestro escribe sincrónicamente en las réplicas de lectura en cada escritura. Aunque este modelo garantiza que las réplicas de solo lectura siempre tengan los datos más recientes, hace que las escrituras sean bastante caras (y causa problemas de disponibilidad para las escrituras) porque el maestro tiene que escribir en todas las réplicas disponibles antes de que regrese.
En los modelos asincrónicos, las réplicas de solo lectura obtienen los datos de una secuencia o un registro de replicación. Los modelos asincrónicos hacen que las escrituras sean más rápidas, pero presentan un retraso entre el maestro y las réplicas de solo lectura. Los usuarios tienen que tolerar el retraso y deben monitorearlo para identificar interrupciones de replicación.
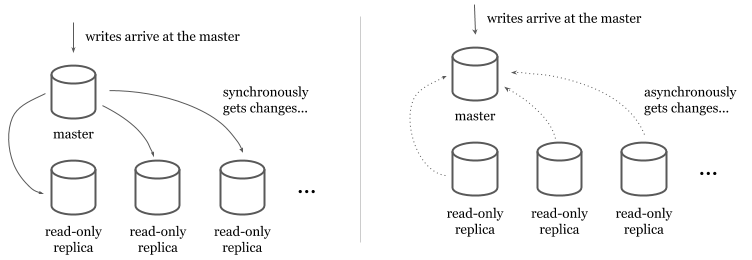
Si bien las lecturas de escalado se pueden abordar con más réplicas de solo lectura, los maestros de escalado son un problema más difícil sin comprometer la consistencia de los datos. Si un maestro falla, otro (s) puede proporcionar datos sin que los usuarios experimenten tiempo de inactividad, pero la replicación multimaestro a menudo se implementa con una replicación asincrónica que impacta negativamente en el sistema general al introducir:
- Características de consistencia más flojas que violan las promesas de ACID.
- Mayor riesgo de tiempos de espera y latencia de comunicación.
- Necesidad de resolución de conflictos entre dos o más maestros si ocurrieron actualizaciones conflictivas pero no se comunicaron.
Debido a la complejidad y los modos de falla que presenta la replicación multimaestro, no es una forma comúnmente preferida de proporcionar alta disponibilidad en la práctica.
Como alternativa, los clústeres de alta disponibilidad son una opción más popular. En este modelo, tendría un clúster completo que puede asumir el control cuando el maestro primario deja de funcionar. Hoy, los proveedores de la nube implementan este modelo para proporcionar características de alta disponibilidad para sus productos de bases de datos relacionales tradicionales administrados.

Topología
Spanner no utiliza clústeres de alta disponibilidad, pero aborda el problema desde un ángulo diferente. Un clúster Spanner * contiene múltiples lecturas de escritura, puede contener algunas réplicas de solo lectura y algunas de testigo.
- Las réplicas de lectura y escritura sirven para leer y escribir.
- Las réplicas de solo lectura sirven lecturas.
- Los testigos no entregan datos pero participan en la elección del líder.
Las réplicas de solo lectura y testigos solo se usan para clústeres de Spanner multirregionales que pueden abarcar varias regiones geográficas. Los clústeres de región única solo usan réplicas de lectura-escritura. Cada réplica vive en una zona diferente en la región para evitar un solo punto de falla debido a interrupciones zonales.

Splits
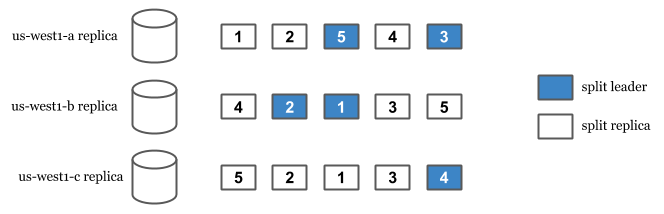
Las capacidades de replicación y fragmentación de Spanner provienen de sus divisiones. Spanner divide los datos para replicarlos y distribuirlos entre las réplicas. La división se produce automáticamente cuando Spanner detecta una carga de lectura o escritura alta entre los registros. Cada división se replica y tiene una réplica líder .
Cuando llega una escritura, encontramos la división en la que se encuentra la fila. Luego, buscamos el líder de esa división y encaminamos la escritura hacia el líder. Esto es cierto incluso en configuraciones de varias regiones donde el usuario está geográficamente más cerca de otra réplica de lectura-escritura no líder. En el caso de una interrupción del líder, se elige una réplica de lectura-escritura disponible como líder y la escritura del usuario se sirve desde allí.
Para que una escritura tenga éxito, un líder debe replicar sincrónicamente el cambio en las otras réplicas. Pero, ¿no está afectando negativamente la disponibilidad de las escrituras? Si las escrituras necesitan esperar a que todas las réplicas tengan éxito, una réplica puede ser un punto único de falla porque las escrituras no tendrán éxito hasta que todas las réplicas repliquen el cambio.
Aquí es donde Spanner hace algo mejor. Spanner solo requiere que la mayoría de los votantes de Paxos escriban con éxito . Esto permite que las escrituras tengan éxito incluso cuando una réplica de lectura-escritura deja de funcionar. Solo se requiere la mayoría de los votantes, no todas las réplicas de lectura-escritura.
Replicación sincrónica
Como se mencionó anteriormente, la replicación sincrónica es difícil e impacta negativamente en la disponibilidad de las escrituras. Por otro lado, cuando la replicación ocurre de forma asíncrona, causan inconsistencias, conflictos y, a veces, pérdida de datos. Por ejemplo, cuando un maestro deja de estar disponible debido a un problema de red, aún puede haber confirmado cambios pero puede que no los haya entregado al maestro secundario. Si el maestro secundario actualiza los mismos registros después de una conmutación por error, puede producirse la pérdida de datos o puede ser necesaria la resolución de conflictos. PostgreSQL proporciona una variedad de modelos de replicación con diferentes compensaciones. El resumen de compensaciones a continuación puede darle una idea de muy alto nivel de las diferentes preocupaciones de las que preocuparse al diseñar modelos de replicación.

La replicación de Spanner es sincrónica . Los líderes deben comunicarse sincrónicamente con otras réplicas de lectura / escritura sobre el cambio y confirmarlo para que una escritura tenga éxito.
Compromiso en dos fases (2PC)
Si bien las escrituras que solo afectan a una división simple usan un protocolo más simple y rápido, si se requieren dos o más divisiones para una transacción de escritura, se ejecuta el compromiso de dos fases (2PC). 2PC es infamemente conocido como "el protocolo de anti-disponibilidad" porque requiere la participación de todas las réplicas y cualquier réplica puede ser un punto único de falla. Spanner todavía sirve escrituras incluso si algunas de las réplicas no están disponibles, porque solo se requiere la mayoría de las réplicas de votación para cometer una escritura.
Red
Spanner es un sistema distribuido y está inherentemente afectado por problemas que están afectando a los sistemas distribuidos en general. La red en sí es un factor de interrupciones en los sistemas distribuidos. Por otro lado, Google cita que solo el 7.6% de las fallas de Spanner estaban relacionadas con las redes. Esto se debe principalmente a que se ejecuta en la red privada de Google. Años de madurez operativa, recursos reservados, tener control sobre las actualizaciones y el hardware hacen que las redes no sean una fuente importante de interrupciones. El artículo anterior de Eric Brewer explica el papel de las redes en este caso con más detalle.
Coloso
Las garantías de durabilidad de Spanner provienen del sistema de archivos distribuido de Google, Colossus. Spanner también mitiga más riesgos al depender de Colossus. El uso de Colossus nos permite desacoplar el almacenamiento de archivos del servicio de base de datos. Spanner es una arquitectura de "nada compartido" y dado que cualquier servidor en un clúster puede leer de Colossus, las réplicas pueden recuperarse rápidamente de fallas de toda la máquina.
Colossus también proporciona replicación y encriptación. Si una instancia de Colossus se cae, Spanner aún puede trabajar en los datos a través de las instancias de Colossus disponibles. Colossus cifra los datos y esta es la razón por la cual Spanner proporciona cifrado en reposo de forma predeterminada.

Las réplicas de lectura y escritura de Spanner transfieren los datos a Colossus, donde los datos se replican 3 veces. Dado que hay tres réplicas de lectura y escritura en un clúster de Spanner, esto significa que los datos se replican 9 veces.
Reintentos automáticos
Como se mencionó anteriormente, Spanner es un sistema distribuido y no es mágico. Experimenta más abortos internos y tiempos de espera que las bases de datos tradicionales al escribir. Una estrategia común en los sistemas distribuidos para hacer frente a fallas parciales y temporales es volver a intentarlo. Las bibliotecas de cliente de Spanner proporcionan reintentos automáticos para transacciones de lectura / escritura . En el siguiente fragmento de Go, verá las API para crear una transacción de lectura y escritura. El cliente vuelve a intentar automáticamente el cuerpo si falla debido a abortos o conflictos:
importar "cloud.google.com/go/spanner"
_, err: = client.ReadWriteTransaction (ctx, func (contexto ctx.Context, txn * spanner.ReadWriteTransaction) error {
// Código de usuario aquí.
}) Uno de los desafíos de desarrollar el soporte de marco ORM para Google Cloud Spanner fue el hecho de que la mayoría de los ORM no tenían reintentos automáticos, por lo tanto, sus API no les dieron a los desarrolladores la sensación de que no deberían mantener ningún estado de aplicación en el alcance de una transacción . Por el contrario, las bibliotecas de Spanner se preocupan por muchos reintentos y se esfuerza por entregarlos automáticamente sin crear una carga adicional para el usuario.
-
Los enfoques de Spanner para fragmentación y replicación son diferentes a las bases de datos relacionales tradicionales. Utiliza la infraestructura de Google y afina varios problemas tradicionalmente difíciles para proporcionar alta disponibilidad sin comprometer la consistencia.
Notas al pie:
(*) La terminología de Google Cloud Spanner para un clúster es una instancia. Evité usar "instancia" porque es un término sobrecargado y podría significar "réplica" para la mayoría de los lectores de este artículo.
(**) La escritura se enruta al líder dividido . Lea la sección Splits para más información.
Este artículo está archivado en spanner.fyi/ha-writes .
¿Cómo evita Spanner un punto único de fallas en las escrituras? se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.