Catálogo de datos en la nube de Google: sincronización en vivo de los cambios de metadatos de su servidor Hive local
Catálogo de datos en la nube de Google: sincronización en vivo de los cambios de metadatos de su servidor Hive local
Muestras de código con un enfoque práctico sobre cómo ingerir incrementalmente los cambios de metadatos de un servidor Hive local en el Catálogo de datos de Google Cloud

Descargo de responsabilidad: todas las opiniones expresadas son mías y no representan a nadie más que a mí ... Vienen de la experiencia de participar en el desarrollo de conectores de muestra totalmente operativos, disponibles en: github .
El reto
Entrar en el mundo de Big Data no es una tarea fácil, la cantidad de datos puede salirse rápidamente de control. Mire la historia de Uber , sobre cómo manejan 100 petabytes de datos utilizando el ecosistema Hadoop, imagine si cada vez que sincronizaran sus metadatos locales en un Catálogo de datos, se ejecutara una ejecución completa, eso sería poco práctico.
Necesitamos una forma de monitorear los cambios ejecutados en el servidor de Hive, y cada vez que se modifica una Tabla o Base de Datos, capturamos solo ese cambio y lo mantenemos de forma incremental en nuestro Catálogo de Datos.
Si se perdió la última publicación , mostramos la ingesta de metadatos de Hive en las instalaciones en el Catálogo de datos, en ese caso no utilizamos una solución incremental.
Para comprender la situación, una ejecución completa con ~ 1000 mesas tomó casi 20 minutos, incluso si solo 1 mesa hubiera cambiado. En la historia de Uber, eso no sería divertido, ¿verdad?
Nota al margen: en este artículo se asume que tienes cierta comprensión de lo que son Data Catalog y Hive. Si desea obtener más información sobre el Catálogo de datos, lea los documentos oficiales .
Arquitectura de sincronización en vivo
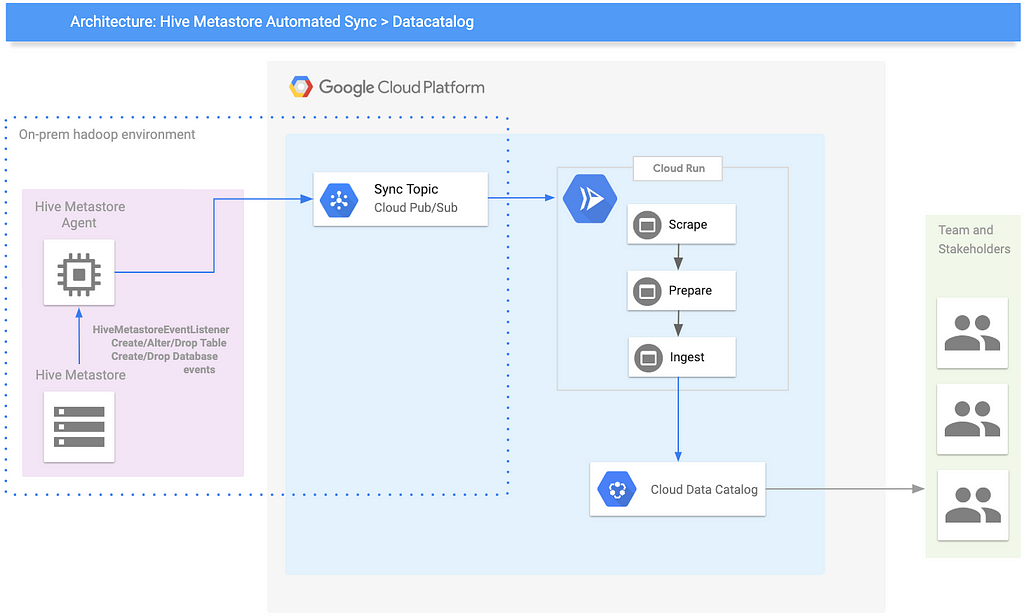
Hay múltiples formas de escuchar los cambios ejecutados en un servidor Hive, este artículo compara dos enfoques: ganchos de Hive x oyentes de Metastore de Hive .
La Arquitectura presentada utiliza un Oyente Metastore Hive, por la simplicidad de tener los metadatos ya analizados.
Lado del entorno Hadoop en las instalaciones
El componente principal aquí es un agente escrito en Java que escucha 5 eventos de Metastore: onAlterTable, onCreateTable, onCreateDatabase, onDropTable, onDropDatabase.

Es un código realmente simple que obtiene el evento y lo envía a un tema de PubSub. Para obtener detalles sobre cómo configurarlo y otros eventos, consulte el repositorio de GitHub .
El agente se ejecuta dentro del proceso Hive Metastore, que debe estar en una red que sea capaz de alcanzar el Proyecto Google Cloud, también la Cuenta de servicio configurada dentro de él necesita el rol de Publicador de publicación / publicación secundaria en el tema.
Lado de Google Cloud Platform
Los componentes principales aquí son PubSub y el conector Hive to Data Catalog .
- PubSub : funciona como una Ingestión de eventos duraderos y capa de sistema de entrega.
- Conector (Scrape / Prepare / Ingest) : esta capa transforma el mensaje Hive Metastore en un activo del Catálogo de datos y lo persiste; para obtener detalles sobre cómo funciona, eche un vistazo a esta publicación .
También tenemos Cloud Run , que funciona como un servidor web de automóvil lateral que recibe el mensaje de PubSub y activa el conector .
Es un código realmente simple que llama a la clase Synchronizer desde el módulo Python hive2datacatalog, que activa los pasos Scrape / Prepare / Ingest.

Para obtener detalles sobre cómo configurar el sidecar de Cloud Run, eche un vistazo al repositorio de conectores de Github .
Disparando el conector
Creemos una nueva base de datos y tabla para verla funcionando
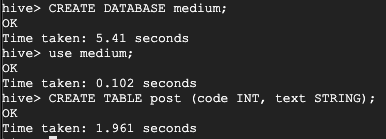
Verificando los registros de Hive Metastore, podemos ver dos mensajes enviados a PubSub

Al ir a Cloud Run, podemos ver el registro de ejecución
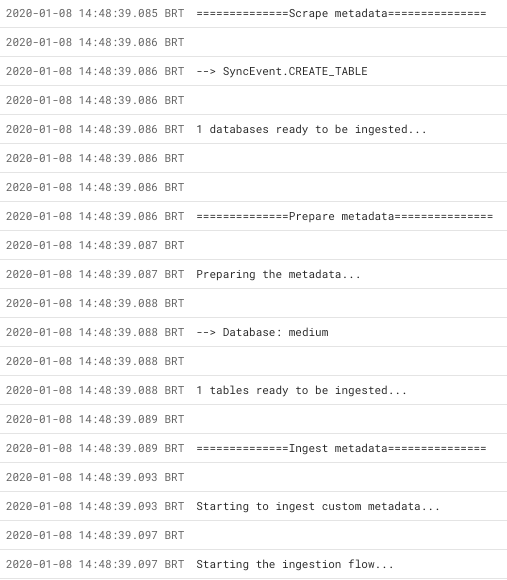
Resultados
Finalmente, abramos las nuevas entradas usando la interfaz de usuario del catálogo de datos
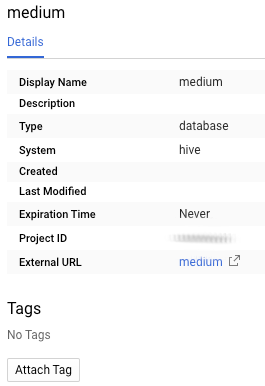


En cuestión de segundos, podemos buscar las entradas recién creadas.
El conector de muestra
Todos los temas tratados en este artículo están cubiertos en un conector de muestra, disponible en GitHub: conectores de colmena . Siéntase libre de obtenerlo y ejecutarlo de acuerdo con las instrucciones. Las contribuciones son bienvenidas, por cierto!
Está licenciado bajo la Licencia Apache Versión 2.0, distribuido "TAL CUAL", SIN GARANTÍAS O CONDICIONES DE NINGÚN TIPO, ya sea expresa o implícita.
Pensamientos finales
En este artículo, hemos cubierto cómo incorporar progresivamente los metadatos de Hive al Catálogo de datos de Google Cloud, de manera escalable y eficiente, lo que permite a los usuarios centralizar su gestión de Metadatos. ¡Estén atentos para nuevas publicaciones que muestran cómo hacer lo mismo con otros sistemas fuente! ¡Salud!
Referencias
- Conector Github Repo : https://github.com/GoogleCloudPlatform/datacatalog-connectors-hive
- Publicación de blog de GA de Data Catalog : https://cloud.google.com/blog/products/data-analytics/data-catalog-metadata-management-now-generally-available
- Documentos oficiales del Catálogo de datos : https://cloud.google.com/data-catalog/
- Muestras de código : https://cloud.google.com/data-catalog/docs/how-to/custom-entries#data-catalog-custom-entry-python
- Ganchos de colmena x Publicación de oyentes de Metastore de Hive : https://towardsdatascience.com/apache-hive-hooks-and-metastore-listeners-a-tale-of-your-metadata-903b751ee99f
Catálogo de datos de Google Cloud: sincronización en vivo Los cambios de metadatos del servidor de Hive en las instalaciones se publicaron originalmente en Google Cloud: Community on Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.