Parte 2: práctica

Visión general
Este documento es la segunda parte de un par que lo ayuda a crear una solución integral para permitir a los analistas de datos un acceso seguro a los datos utilizando herramientas de inteligencia empresarial (BI). La solución utiliza herramientas familiares de código abierto del ecosistema de Hadoop y Tableau como herramienta de BI.
En la primera parte , se centró en la definición de la arquitectura, sus componentes y sus interacciones. En este artículo, verá el proceso de configuración de los componentes de la arquitectura que conforma la topología de Hive de extremo a extremo en Google Cloud.
Este artículo está destinado a operadores y administradores de TI que configuran el entorno que proporciona capacidades de procesamiento y datos a las herramientas de BI utilizadas por los analistas de datos. A lo largo del artículo, utilizará "Mary" como la identidad de usuario ficticia de un analista de datos. Esta identidad de usuario está centralizada en el directorio LDAP utilizado por Apache Knox y Apache Ranger . También puede configurar grupos LDAP, pero esa tarea queda fuera del alcance de este artículo.
Objetivos
- Cree una configuración de extremo a extremo que permita que una herramienta de BI use datos de un entorno Hadoop.
- Autenticar y autorizar solicitudes de usuarios.
- Configure y use canales de comunicación seguros entre la herramienta de BI y el clúster.
Costos
Este artículo utiliza componentes facturables de Google Cloud, que incluyen:
Antes de que empieces
Configurar el proyecto
1.En la Consola de la nube, en la página del selector de proyectos, seleccione o cree un proyecto de la nube.
Nota: Si no planea conservar los recursos que crea en este procedimiento, cree un proyecto en lugar de seleccionar un proyecto existente. Después de completar estos pasos, puede eliminar el proyecto, eliminando todos los recursos asociados con el proyecto.
Ir a la página del selector de proyectos
2. Asegúrese de que la facturación esté habilitada para su proyecto Google Cloud. Aprenda a confirmar que la facturación está habilitada para su proyecto.
3. En Cloud Console, active Cloud Shell.
En la parte inferior de la Consola de nube, se inicia una sesión de Cloud Shell y muestra un indicador de línea de comandos. Cloud Shell es un entorno de shell con Cloud SDK ya instalado, incluida la herramienta de línea de comandos gcloud , y con valores ya establecidos para su proyecto actual. La sesión puede tardar unos segundos en inicializarse.
4. Habilite las API de nube para Dataproc, Cloud SQL y Cloud Key Management Service (KMS) :
5. En Cloud Shell, establezca variables de entorno con la ID de su proyecto y la región y zonas donde se ubicarán los clústeres de Dataproc:
Siéntase libre de elegir una región y zona diferente, pero manténgalas constantes a lo largo de los scripts en este artículo.
Configurar una cuenta de servicio
1.En Cloud Shell, cree una cuenta de servicio que será utilizada por los diferentes productos relacionados con la seguridad de visualización.
2. Agregue los siguientes roles a la cuenta de servicio:
- Dataproc Worker : para crear y administrar clústeres de Dataproc.
- Cloud SQL Editor : para que Ranger se conecte a su base de datos usando Cloud SQL Proxy .
- Cloud KMS CryptoKey Decrypter : para descifrar las contraseñas previamente cifradas con KMS.
Crear el clúster de fondo
Crear la instancia de la base de datos Ranger
1. Ejecute el siguiente comando para crear una instancia de MySQL para almacenar las políticas de Apache Ranger. El comando crea una instancia llamada cloudsql-mysql con el tipo de máquina db-n1-standard-1 ubicado en la región especificada por la variable $ {REGION}. Consulte la documentación de Cloud SQL para obtener más información.
2. Establezca la contraseña de la instancia para el usuario root que se conecta desde cualquier host ('root' @ '%'). Puede usar su propia contraseña o la que se proporciona como ejemplo a continuación. Asegúrese de utilizar un mínimo de ocho caracteres, incluyendo al menos una letra y un número.
Cifrar las contraseñas
En esta sección, creará una clave criptográfica para cifrar las contraseñas de Ranger y MySQL. Para evitar la exfiltración, la clave se encuentra dentro del Servicio de administración de claves (KMS) y no puede ver, extraer ni exportar los bits de la clave.
Utiliza la clave para cifrar las contraseñas y escribirlas en archivos. Luego carga estos archivos en un depósito de Cloud Storage para que sean accesibles para la cuenta de servicio que actúa en nombre de los clústeres.
La cuenta de servicio puede descifrar esos archivos porque tiene el rol cloudkms.cryptoKeyDecrypter y el acceso a los archivos y la clave criptográfica. En el caso poco probable de que un archivo se filtre, un atacante no podría descifrarlo sin la función y la clave.
Como medida de seguridad adicional, crea archivos de contraseña separados para cada servicio para minimizar el radio de explosión en caso de que se filtre una contraseña.
Para obtener más información sobre la administración de claves, consulte la documentación de KMS .
1.En Cloud Shell, cree un conjunto de claves del Servicio de administración de claves (KMS) para guardar sus claves:
2. Cree una clave criptográfica del Servicio de administración de claves (KMS) para cifrar sus contraseñas:
3. Cifre la contraseña de su usuario administrador de Ranger con la clave. Puede usar su propia contraseña o la que se proporciona como ejemplo a continuación. Asegúrese de utilizar un mínimo de ocho caracteres, incluyendo al menos una letra y un número.
4. Cifre la contraseña del usuario administrador de la base de datos Ranger con la clave:
5. Cifre su contraseña de root de MySQL usando la clave:
6. Cree un depósito de Cloud Storage para almacenar archivos de contraseña cifrados:
7. Cargue los archivos de contraseña cifrados en el depósito de Cloud Storage.
Crea el cluster
En esta sección, creará un clúster back-end con soporte de Ranger. Para obtener más información sobre el componente opcional Ranger en Dataproc, consulte la página de documentación del Componente Ranger Dataproc .
1.En Cloud Shell, cree un depósito de Cloud Storage para almacenar los registros de auditoría de Apache Solr:
2. Exporte todas las variables necesarias para crear el clúster. Algunas variables que se establecieron antes se repiten aquí por conveniencia, por lo que puede modificarlas según sea necesario.
Las nuevas variables son:
- El nombre del clúster de fondo
- El URI de la clave criptográfica para que la cuenta de servicio pueda descifrar las contraseñas.
- El URI de los archivos que contienen las contraseñas cifradas.
Si ha utilizado un conjunto de claves, claves o nombres de archivo diferentes, reemplácelos en las variables correspondientes.
3. Ejecute el siguiente comando para crear el clúster de back-end Dataproc:
Las últimas tres líneas son las propiedades de Hive para configurar HiveServer2 en modo HTTP, para que Apache Knox pueda llamar a Apache Hive a través de HTTP.
Estos son otros parámetros que aparecen en el comando:
- - opcional-components = SOLR, RANGER habilita Apache Ranger y su dependencia Solr
- - enable-component-gateway (opcional) habilita Dataproc Component Gateway para que Ranger y otras interfaces de usuario de Hadoop estén disponibles directamente desde la página del clúster en Cloud Console sin la necesidad de hacer un túnel SSH hacia el nodo maestro de back-end.
- - scopes = default, sql-admin autoriza a Apache Ranger a acceder a su base de datos Cloud Cloud.
Es posible incluir parámetros y propiedades adicionales para crear un Metastore externo de Hive que persista más allá de la vida útil de cualquier clúster dado y se pueda usar en varios clústeres. Consulte la documentación sobre el uso de Apache Hive en Cloud Dataproc para obtener más información.
Tenga en cuenta que los trabajos de gcloud dataproc que envían comandos de Hive usan el transporte binario de Hive y no son compatibles con HiveServer2 configurado en modo HTTP. Por lo tanto, debe ejecutar los ejemplos de creación de tablas en esa documentación directamente en Beeline.
Crear una tabla de muestra de Hive
1.En Cloud Shell, cree un depósito de Cloud Storage para almacenar un archivo Apache Parquet de muestra:
2. Copie un archivo de Parquet de muestra disponible públicamente en su bucket:
3. Conéctese mediante SSH al nodo maestro del clúster de fondo que creó en la sección anterior.
El nombre del nodo maestro del clúster es el nombre del clúster seguido de -m. Para los clústeres HA, el nombre tiene un sufijo adicional .
Si es la primera vez que se conecta a su nodo maestro desde Cloud Shell, se le pedirá que genere claves SSH.
Alternativamente, puede conectarse mediante SSH a su nodo de nombre desde la consola de la nube en Dataproc / Cluster Details / VM Instances.
4. Una vez en el símbolo del sistema SSH, conéctese al HiveServer2 local utilizando Apache Beeline , que está preinstalado en el nodo maestro.
Este comando iniciará Beeline CLI y pasará el nombre de su proyecto Google Cloud en una variable de entorno.
Tenga en cuenta que Hive no realiza ninguna autenticación de usuario, pero requiere una identidad de usuario para realizar la mayoría de las tareas. El usuario administrador aquí es un usuario predeterminado configurado en Hive. La autenticación de usuario para solicitudes provenientes de las herramientas de BI es manejada por el proveedor de identidad configurado más adelante en este artículo con Apache Knox.
5. En la CLI de Beeline, cree una tabla usando el archivo Parquet previamente copiado en su depósito Hive.
6. Verifique que la tabla se haya creado correctamente:
7. Salga de Beeline CLI:
8. Tome nota del nombre DNS interno del maestro de back-end. Utiliza este nombre en la siguiente sección como
9. Salga de la línea de comando SSH:
Crear el clúster proxy
En esta sección, creará el clúster proxy con la Acción de inicialización de Apache Knox .
Crear una topología
1.En Cloud Shell, clone el repositorio GitHub de acciones de inicialización de Dataproc .
2. Cree una topología para el clúster de fondo:
Apache Knox usará el nombre del archivo como la ruta URL para la topología. Aquí cambió el nombre para representar una topología llamada hive-us-transacciones para acceder a los datos de las transacciones ficticias que cargamos a Hive en la sección anterior.
3. Edite el archivo de topología:
Tómese un momento para observar el archivo descriptor de topología . Este archivo define una topología que apunta a uno o más servicios de back-end. Dos servicios están configurados con valores de muestra: WebHDFS y HIVE . El archivo también define el proveedor de autenticación para los servicios en esta ACL de topología y autorización.
4. Apache Knox proporciona una autorización general en el nivel de servicio a través de ACL. Agregue la identidad de usuario de LDAP de muestra de analista de datos "Mary" para que pueda acceder al servicio de back-end de Hive a través de Knox.
5. Cambie la URL de HIVE para que apunte al servicio de Hive del clúster de fondo. Puede encontrar la definición del servicio HIVE en la parte inferior del archivo, justo debajo del servicio WebHDFS.
Reemplace la
6. Guarde el archivo y cierre el editor .
En este punto, puede crear topologías adicionales repitiendo los pasos de esta sección y creando un descriptor XML independiente por topología.
En una sección posterior, copiará estos archivos en un depósito de Cloud Storage. Para crear nuevas topologías o cambiarlas después de crear el clúster proxy, modifique los archivos y cárguelos nuevamente al depósito. La acción de inicialización crea un trabajo cron que copia regularmente los cambios del depósito al clúster proxy.
Configure el certificado SSL / TLS
Cuando los clientes se comunican con Apache Knox, utilizarán un certificado SSL / TLS. La acción de inicialización puede generar un certificado autofirmado o puede proporcionar su certificado firmado por CA.
Para generar un certificado autofirmado, siga estas instrucciones:
1.En Cloud Shell edite el archivo de configuración general de Apache Knox:
2. Reemplace HOSTNAME por el nombre DNS externo de su nodo maestro como el valor para el atributo nombre_host_certificado. Para fines de demostración, use localhost. Este valor necesita que cree un túnel SSH entre su máquina local y el clúster proxy, que se trata más adelante en este artículo.
Tenga en cuenta que este archivo también contiene la master_key que se usa para cifrar los certificados que las herramientas de BI usarán para comunicarse con el clúster proxy. Por defecto, esta clave es la palabra secreto.
3. Guarde el archivo y cierre el editor.
Por otro lado, si proporciona su propio certificado, puede especificarlo en la propiedad custom_cert_name.
Gire el clúster proxy
1.En Cloud Shell, cree un depósito de Cloud Storage para proporcionar las configuraciones de la sección anterior a la acción de inicialización de Knox:
2. Copie todos los archivos de la carpeta de acción de inicialización de Knox en el depósito:
3. Exporte todas las variables necesarias para crear el clúster. Algunas variables que se configuraron anteriormente se repiten aquí por conveniencia para que pueda modificarlas según sea necesario.
4. Cree el clúster proxy:
Verificar la conexión a través del proxy
1.Después de crear el clúster proxy, conéctese a su nodo maestro utilizando SSH de Cloud Shell:
2. Ejecute una consulta desde el símbolo del sistema SSH del nodo maestro del clúster proxy:
Analicemos el comando:
- El comando beeline usa localhost en lugar del nombre interno de DNS porque el certificado que generó cuando configuró Knox especifica localhost como el nombre de host. Si está utilizando su propio nombre DNS o certificado, use el nombre de host correspondiente.
- El puerto es 8443, que corresponde al puerto SSL predeterminado de Apache Knox.
- La siguiente línea habilita SSL y proporciona la ruta y la contraseña para SSL Trust Store para que las utilicen las aplicaciones cliente como Beeline.
- La línea transportMode debería parecer familiar. Indica que la solicitud debe enviarse a través de HTTP y proporciona la ruta para el servicio HiveServer2. Tenga en cuenta que la ruta se compone de la puerta de enlace de palabras clave, seguida del nombre de topología que definió en una sección anterior, seguido del nombre del servicio configurado en dicha topología, en este caso colmena.
- Con el parámetro -e, proporciona la consulta para que se ejecute en Hive. Si se omite, abrirá una sesión interactiva en Beeline CLI.
- Con el parámetro -n, proporciona una identidad de usuario y contraseña. En este caso, está utilizando el usuario administrador predeterminado de Hive. En las siguientes secciones, creará una identidad de usuario analista y configurará credenciales y políticas de autorización para este usuario.
Agregar usuario a la tienda de autenticación
Por defecto, Knox incluye un proveedor de autenticación basado en Apache Shiro configurado con autenticación BÁSICA contra un almacén LDAP de ApacheDS . En esta sección, agregará un ejemplo de identidad de usuario del analista de datos "Mary" a este almacén de autenticación.
- En el símbolo del sistema del nodo maestro proxy SSH, instale las utilidades LDAP:
2. Cree un archivo de formato de intercambio de datos LDAP (LDIF) para el nuevo usuario "Mary":
3. Agregue la ID de usuario al directorio LDAP:
El parámetro -D especifica el nombre distinguido (DN) para vincular al acceder al directorio, que debe ser una identidad de usuario que ya esté en el directorio, en este caso el usuario administrador.
4. Verifique que se haya agregado el nuevo usuario:
5. Tome nota del nombre DNS interno del maestro proxy. Utiliza este nombre en la siguiente sección como
6. Salga de la línea de comando SSH
Configurar autorización
Sincronizar identidades de usuario en Ranger
Para asegurarse de que las políticas de Ranger se apliquen a las mismas identidades de usuario utilizadas por Knox, configure el demonio Ranger UserSync para sincronizar las identidades del mismo directorio que Knox está utilizando.
En este ejemplo, se conecta al LDAP local que está disponible de forma predeterminada con Apache Knox, pero en un entorno de producción debe configurar un directorio de identidad externo. Puede encontrar más información en la guía del usuario de Apache Knox y en la documentación de Cloud Identity , Managed Active Directory y Federated AD de Google Cloud.
1.Conéctese al nodo maestro del clúster de back-end que creó anteriormente con SSH
2. Edite el archivo de configuración de UserSync:
3. Establezca los valores de las siguientes propiedades LDAP. Asegúrese de modificar las propiedades del usuario y no las propiedades del grupo, que tienen nombres similares.
Reemplace la
Tenga en cuenta que este es un subconjunto de una configuración LDAP completa que sincroniza usuarios y grupos. Vea esta documentación para más información.
4. Guarde el archivo y cierre el editor.
5. Reinicie el demonio Ranger UserSync:
Puede verificar que las identidades de los usuarios, incluida la del analista de datos Mary, estén sincronizadas correctamente en el archivo de registro en / var / log / ranger-usersync /
Crear políticas de guardabosques
Configurar el servicio de guardabosques
1.En el símbolo del sistema SSH del nodo maestro, edite la configuración de Ranger Hive:
2. Edite el
3. Guarde el archivo y cierre el editor.
4. Reinicie el servicio de administración de HiveServer2. Estás listo para crear políticas de guardabosques.
Configure el servicio en la interfaz de usuario de administración del guardabosques
1.En un navegador, navegue a la página Dataproc en Cloud Console.
Haga clic en el nombre del clúster de fondo y luego en Interfaces web .
Debido a que creó su clúster con Component Gateway , debería ver una lista de los componentes de Hadoop que están instalados en su clúster.
Haga clic en el enlace Ranger para abrir la interfaz de usuario de Ranger.
Si prefiere no crear su clúster con Component Gateway, puede crear un túnel SSH desde su estación de trabajo hacia el nodo maestro de fondo. La interfaz de usuario de Ranger está disponible en el puerto 6080 . Deberá crear una regla de firewall para abrir la entrada a ese puerto.
2. Inicie sesión en Ranger con el administrador de usuario y la contraseña de administrador de Ranger que definió previamente. La interfaz de usuario de Ranger muestra la pantalla del administrador de servicios con una lista de servicios.
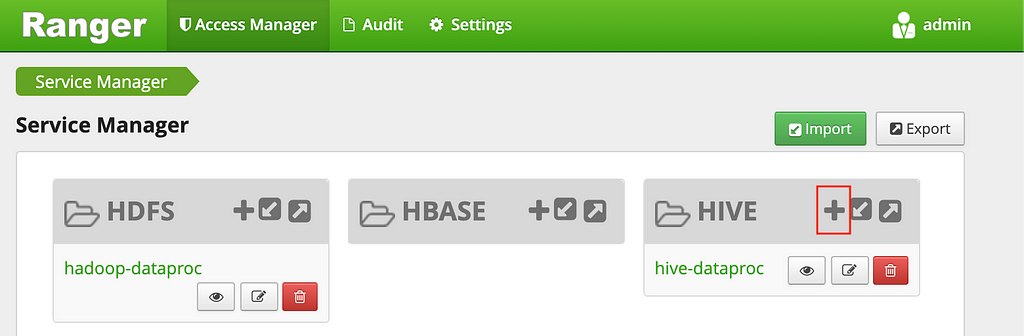
3. Haga clic en el signo más en el grupo HIVE para crear un nuevo servicio de Hive
4. Complete el formulario con los siguientes valores:
- Nombre del servicio: ranger-hive-service-01. Este es el nombre que definió previamente en el archivo de configuración ranger-hive-security.xml.
- Nombre de usuario: admin
- Contraseña: contraseña de administrador
- jdbc.driverClassName: deje el org.apache.hive.jdbc.HiveDriver predeterminado
- jdbc.url: jdbc: hive2: //
: 10000 /; transportMode = http; httpPath = cliservice
Reemplace la
5. Haga clic en el botón Agregar .
Tenga en cuenta que cada instalación del complemento Ranger solo admite un servicio de Hive . Una manera fácil de configurar servicios adicionales de Hive es activar clústeres de back-end adicionales, cada uno con su propio complemento Ranger. Estos clústeres pueden compartir la misma base de datos de Ranger, de modo que tenga una vista unificada de todos los servicios siempre que acceda a la IU de administrador de Ranger desde cualquiera de esos clústeres.
Configurar una política de guardabosques
Esta política permite al usuario de analista de muestras LDAP "mary" acceder a columnas específicas de la tabla Hive:
1.Vuelva a la pantalla del Administrador de servicios, haga clic en el nombre del servicio que acaba de crear.
Ranger Admin muestra la pantalla de Políticas.
2. Haga clic en el botón Agregar nueva política .
Con esta política, le dará permiso a Mary para ver solo las columnas submitDate y transactionType de las transacciones de la tabla.
3. Rellene el formulario con los siguientes valores:
- Nombre de la política: cualquier nombre, por ejemplo allow-tx-columnas
- Base de datos: predeterminada
- Tabla: transacciones
- Columna de la colmena: submitDate, transactionType
Permitir condiciones:
- Seleccionar usuario: mary
- Permisos: seleccione
4. Haga clic en Agregar en la parte inferior de la pantalla.
Probar la política con Beeline
1.Vuelva en el símbolo del sistema SSH del nodo maestro, ingrese la Beeline CLI con el usuario "mary". Tenga en cuenta que la contraseña no se aplica.
2. Ejecute la siguiente consulta para verificar que Ranger la bloquea. (Incluye la columna transacciónAmount, que Mary no puede seleccionar):
Debería obtener un error de Permiso denegado .
3. Ejecute la siguiente consulta para verificar que Ranger lo permita:
4. Salga de Beeline CLI.
5. Salga de la línea de comando SSH.
6. De vuelta en la IU de Ranger, haga clic en la pestaña Auditoría en la parte superior. Debería ver los eventos denegados y permitidos . Puede filtrar los eventos por el nombre del servicio que definió anteriormente, por ejemplo: ranger-hive-service-01.

Conectarse desde una herramienta de BI
El último paso en este artículo es consultar los datos de Hive desde herramientas de BI como Tableau y Looker. Utilizamos Tableau como ejemplo de una herramienta de BI, por lo que asumimos que tiene Tableau Desktop ejecutándose en su estación de trabajo.
Crear una regla de firewall
- Tome nota de su dirección IP pública .
- En Cloud Shell, cree una regla de firewall que abra el puerto TCP 8443 para ingresar desde su estación de trabajo.
Reemplace la
3. Aplique la etiqueta de red de la regla del firewall al nodo maestro del clúster proxy:
4. Tome nota de la dirección IP externa del nodo maestro del clúster proxy; lo usará en los siguientes pasos:
Crea un túnel SSH
Este paso solo es necesario si está utilizando un certificado autofirmado válido para localhost. Si está utilizando su propio certificado o su nodo maestro tiene su propio nombre DNS externo, puede omitir este paso.
1.En Cloud Shell, genere el comando para crear el túnel:
2. Instale el SDK de Google Cloud en su estación de trabajo.
3. Ejecute gcloud init para autenticar su cuenta de usuario y otorgar permisos de acceso.
4. Abra una terminal en su estación de trabajo.
5. Cree un túnel SSH para reenviar el puerto 8443.
6. Copie el comando generado en el primer paso y péguelo en el terminal de la estación de trabajo. Ejecute el comando
7. Deje la terminal abierta para que el túnel permanezca activo.
Conéctate a la colmena
1.Instale el controlador ODBC de Hive en su estación de trabajo.
2. Abra Tableau Desktop o reinícielo si estaba abierto.
3. En la pantalla de inicio en Conectar / a un servidor , seleccione Más ...
4. Busque y seleccione Cloudera Hadoop .
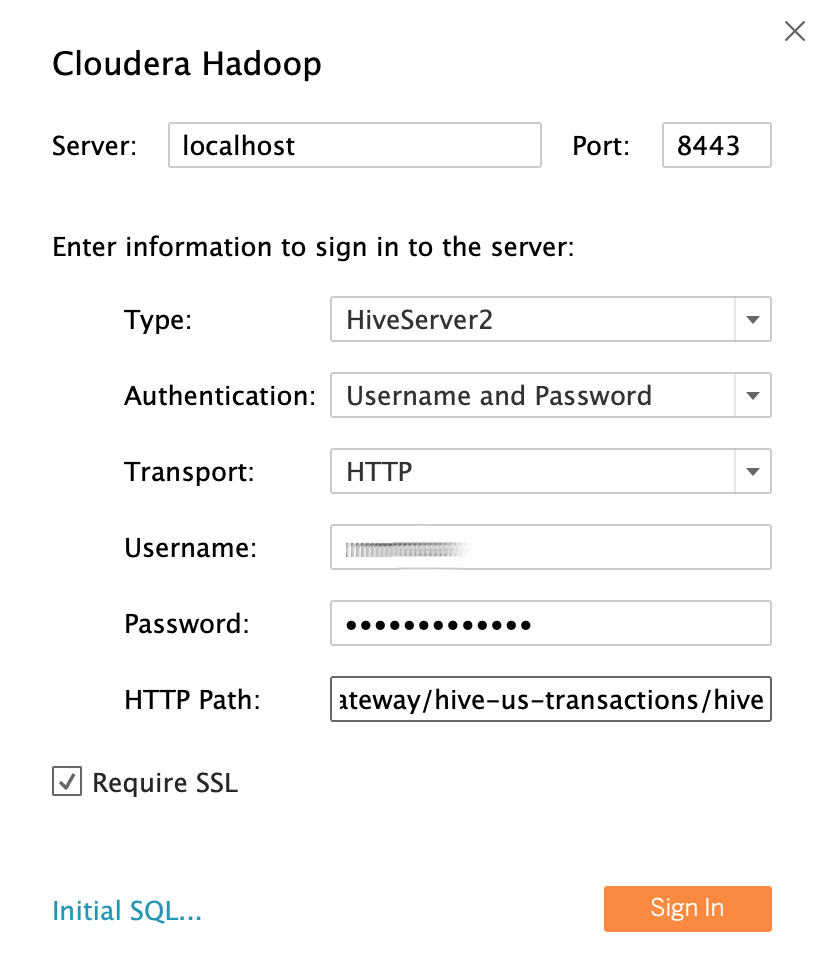
5. Complete los campos de la siguiente manera:
- Servidor: localhost si creó un túnel, o el nombre DNS externo de su nodo maestro si no.
- Puerto: 8443
- Tipo: HiveServer2
- Autenticación: nombre de usuario y contraseña
- Nombre de usuario: mary
- Contraseña: Mary-Password
- Ruta HTTP: gateway / hive-us-connections / hive
- Requerir SSL: sí
Tenga en cuenta que está utilizando el analista de datos de muestra LDAP user mary como identidad de usuario.
6. Haga clic en Iniciar sesión.
Consultar datos de Hive
1.En la pantalla Origen de datos , haga clic en Seleccionar esquema ay busque el valor predeterminado.
2. Haga doble clic en el nombre de esquema predeterminado.
El panel de mesa se carga.
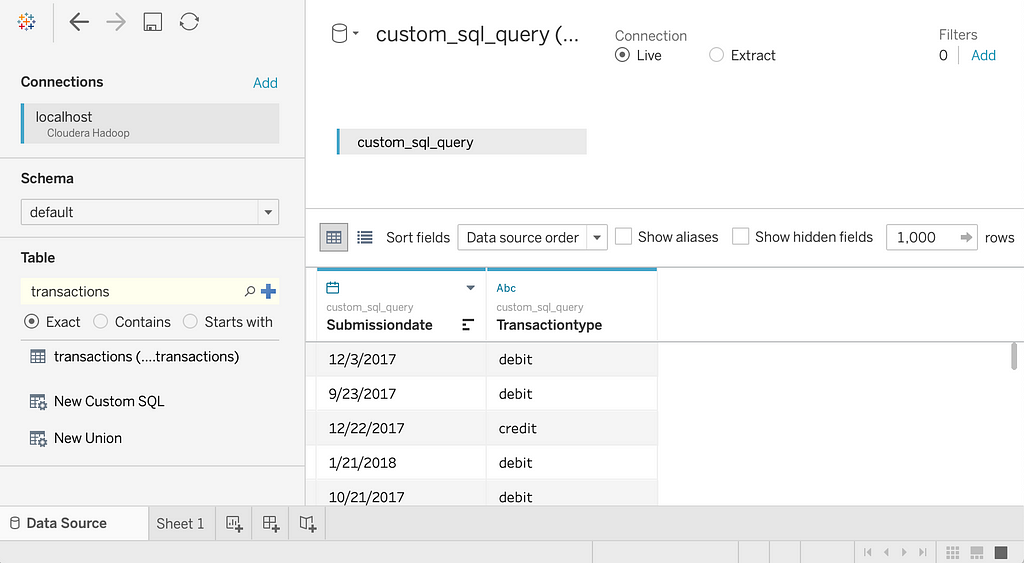
3. En el panel Tabla , haga doble clic en Nuevo SQL personalizado .
Se abre la ventana Editar SQL personalizado .
4. Ingrese la siguiente consulta:
5. Haga clic en Aceptar.
Los metadatos para la consulta se recuperan de Hive.
6. Haga clic en el botón Actualizar ahora .
Tableau recupera los datos de Hive.
7. Ahora intente seleccionar todas las columnas de la tabla de transacciones. En el panel Tabla , vuelva a hacer doble clic en Nuevo SQL personalizado . Se abre la ventana Editar SQL personalizado .
8. Ingrese la siguiente consulta:
9. Haga clic en Aceptar . Recibe un mensaje de error:
Permiso denegado: el usuario [mary] no tiene el privilegio [SELECT] en [default / connections / *].
Esto se espera porque Mary no está autorizada por Ranger para leer la columna transacciónAmount. De esta manera, puede limitar a qué datos pueden acceder sus usuarios de Tableau.
Para poder ver todas las columnas, repita los pasos con el administrador de usuario.
Conclusión
En estos artículos ha visto cómo puede acceder a los datos de Hive desde una herramienta de BI. Ha configurado Tableau para comunicarse a través de un canal seguro con Apache Knox que se ejecuta en un clúster Dataproc, y ha autenticado a un usuario con un directorio LDAP. Finalmente, ha configurado un servicio Hive que puede procesar la solicitud en clústeres de back-end de Dataproc, protegiendo aún más los datos mediante políticas de autorización definidas en Apache Ranger.
Conectar su software de visualización a Hadoop en Google Cloud se publicó originalmente en Google Cloud - Community on Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.